
Metodologie a podpůrný nástroj pro snadné vytváření flexibilních objektových aplikací
Hradec Králové
jaro 2003
Architektura podřízená modelu
Práce v teoretické části zkoumá jednotlivé části typické obchodní aplikace. Jejím cílem je shrnout běžné postupy v řešení nalezených částí, určit, které z nich jsou nevhodné zejména z hlediska dlouhodobé nezávislosti, flexibility a schopnosti změny, na základě nalezených chyb definovat stručné a jasné obecné zásady pro správná řešení a najít řešení, která jsou v souladu s těmito zásadami. Námětem praktické části je Xermes, klient/server systém pro zpřístupnění objektů aplikace uživatelskému rozhraní. Práci na něm jsem zahájil, protože jsem nenašel žádné vyhovující řešení v souladu s požadavky definovanými v oblasti uživatelského rozhraní.
Architecture subordinate to model
The theoretical section of the document examines parts of a business application one-to-one. The main aim of the part is to summarize common ways to work the found parts out, to distinguish, which of them are inadvisable primarily becouse of lack of long term independence, flexibility and ability to change, to define concise and clear general rules of proper solutions on this ground and to find advisable solutions, the ones in harmony with the general rules. The subject of the practical part is Xermes, client/server framework able to bring objects of application to user interface. I started development of it, becouse of current lack of solutions in conformance with rules defined in user interface area.
Copyright © Informace, které jsou v tomto dokumentu zveřejněny mohou být chráněny jako patent. Jména produktů jsou použita bez záruky jejich volného použití. Některé názvy mohou být registrovanými známkami nebo jinak chráněny. Při sestavování textu jsem se snažil postupovat pečlivě, nicméně nemohu poskytnout záruku bezchybnosti. Všechna práva vyhrazena. Žádná část nesmí být reprodukována a distribuována bez předchozího svolení autora. Výjimku tvoří zveřejnění krátkých části textu pro akademické, nekomerční účely a pro účely recenzí, vždy ale musí být uveden zdroj včetně adresy http://www.evidence.cz/zefa/asm.
Obsah
- 1. Úvod
- 1.1. Cíl práce
- 1.2. Čtenář
- 1.3. Vymezení domén
- 1.3.1. Model
- 1.3.2. Platforma
- 1.3.3. Infrastruktura
- 1.3.4. Úložiště
- 1.3.5. Neuživatelské rozhraní
- 1.3.6. Uživatelské rozhraní
- 1.3.7. A co když...
- 1.4. Postup zkoumání domén
- 1.4.1. Shrnutí možností
- 1.4.2. Běžné chyby
- 1.4.3. Požadavky ASM
- 1.4.4. Řešení v souladu s požadavky
- 2. Model
- 2.1. Shrnutí možností
- 2.2. Běžné chyby
- 2.2.1. Strukturální programování
- 2.2.2. Relační model
- 2.2.3. Model založený na XML
- 2.2.4. Objektový model
- 2.3. Požadavky ASM
- 2.3.1. Požadavek
- 2.4. Řešení v souladu s požadavky
- 3. Platforma
- 3.1. Shrnutí možností
- 3.1.1. Procedurální
- 3.1.2. Logické, deklarativní, pravidlové apod.
- 3.2. Běžné chyby
- 3.3. Požadavky ASM
- 3.3.1. Požadavek
- 3.4. Řešení v souladu s požadavky
- 3.4.1. Jazyky kompilované
- 3.4.2. Jazyky interpretované
- 3.4.3. Jazyky interpretované s bytekompilací
- 4. Infrastruktura
- 4.1. Shrnutí možností
- 4.1.1. Nevrstvená infrastruktura
- 4.1.2. Dvouvrstevná infrastruktura
- 4.1.3. Třívrstevná infrastruktura
- 4.2. Běžné chyby
- 4.3. Požadavky ASM
- 4.3.1. Požadavek
- 4.4. Řešení v souladu s požadavky
- 5. Úložiště
- 5.1. Shrnutí možností
- 5.1.1. Soubory
- 5.1.2. Objektově orientované databázové systémy
- 5.1.3. Objektově-relační mapování
- 5.1.4. Objektově-relační technologie
- 5.1.5. Mnoharozměrné databáze
- 5.1.6. Stromové struktury
- 5.1.7. Snahy o univerzální přístup
- 5.2. Běžné chyby
- 5.3. Požadavky ASM
- 5.3.1. Požadavek
- 5.4. Řešení v souladu s požadavky
- 5.4.1. Jakarta OJB
- 6. Neinteraktivní rozhraní
- 6.1. Shrnutí možností
- 6.1.1. Tiskárna
- 6.1.2. Netiskové výstupy
- 6.2. Běžné chyby
- 6.2.1. Tiskárna
- 6.2.2. Netiskové výstupy
- 6.3. Požadavky ASM
- 6.3.1. Požadavek
- 6.4. Řešení v souladu s požadavky
- 6.4.1. XML
- 7. Uživatelské rozhraní
- 7.1. Shrnutí možností
- 7.1.1. Scénář desktop
- 7.1.2. Scénář z intranetu
- 7.1.3. Scénář z Internetu
- 7.1.4. Scénář mobilní
- 7.1.5. Scénář hendikepovaní
- 7.2. Běžné chyby
- 7.3. Požadavky ASM
- 7.3.1. Požadavek
- 7.4. Řešení v souladu s požadavky
- 8. Výsledky
- 8.1. Shrnutí
- 8.2. ASM aplikace jako celek
- 9. Závěry a doporučení
- A. Xermes - přehled
- A.1. Abstraktní reflexe
- A.2. Server
- A.3. ACIL
- A.4. Klient
- A.4.1. Swing klient
- A.4.2. Jiní klienti
- A.5. Shrnutí
- A.5.1. Přínosy
- A.5.2. Závislosti
- A.5.3. Licence
- A.5.4. Stav a vývoj
- B. Proces vývoje aplikace
- B.1. Proces
- B.2. Modelovací jazyk
- B.3. Řešení problémů nadohled
- B.4. Vztah MDA k ASM
- C. CD
- Bibliografie
Seznam obrázků
- 1. ASM aplikace
- 2. Výsledky uplatnění principu obalu
- 3. Místo modelu v ASM aplikaci
- 4. Příklad strukturálního přístupu s relačním modelem
- 5. Charakter objektu
- 6. Přístup objektového modelu
- 7. Vývoj architektur programů
- 8. Význam platformy v ASM aplikaci
- 9. Proces vytvoření a spuštění kompilovaného programu
- 10. Proces vytvoření a spuštění interpretovaného programu
- 11. Proces vytvoření a spuštění bytekompilovaného programu
- 12. Infrastruktura ASM aplikace
- 13. Samostatná aplikace
- 14. Mohutný klient - úložiště
- 15. Tenký klient - mohutný server
- 16. Třívrstevná infrastruktura
- 17. Místo úložiště v ASM aplikaci
- 18. Tradiční tabulka
- 19. Příklad pohledu podél jiného rozměru
- 20. Architektura OJB
- 21. Místo modelu v ASM aplikaci
- 22. Formáty pro zachycení textové a grafické informace
- 23. Náročnost převodů
- 24. Místo uživatelského rozhraní v ASM aplikaci
- 25. Příklad vzhledu desktop aplikace
- 26. Pull přístup k vytváření dynamického obsahu
- 27. Push přístup k vytváření dynamického obsahu
- 28. Princip XMLC
- 29. ASM aplikace - detailní schéma
- A.1. ASM aplikace - ne všechno je ruční práce
- A.2. Možnosti manipulace s objekty
- A.3. Vrstevnatá architektura
- A.4. Architektura transformátoru
- A.5. Logický vztah ACILu k dalším XML jazykům
- A.6. Xermes Hello world! - vzhled
- A.7. Model adresáře
- A.8. Implementace adresáře
- A.9. Vzhled adresáře
- B.1. Proces vývoje ASM aplikace
- B.2. Iterační vývoj programů
- B.3. UML bude sloužit ve všech fázích existence aplikace
- B.4. Modelem řízený vývoj aplikací
- B.5. Vrstvy MDA standardů
- B.6. ASM a MDA se vhodně doplňují
- B.7. Kombinace ASM a MDA = konzistentní proces vývoje
Seznam příkladů
- 1. Vývoj nekončí odevzdáním
- 2. Prezentace (XHTML)
- 3. Logy, statistika.. (SQL)
- 4. Banka (proprietární)
- 5. Elektronické podání (XML)
- 6. Prezentace (XHTML) pokračování
- 7. Logy, statistika.. (SQL) pokračování
- 8. Banka (proprietární) pokračování
- 9. Elektronické podání (XML) pokračování
- A.1. Přímá práce s objektem
- A.2. Reflexe
- A.3. Introspekce
- A.4. Abstraktní reflexe
- A.5. Jednoduchý ACIL dokument
- A.6. Xermes Hello world! - kód
- 1.1. Cíl práce
- 1.2. Čtenář
- 1.3. Vymezení domén
- 1.3.1. Model
- 1.3.2. Platforma
- 1.3.3. Infrastruktura
- 1.3.4. Úložiště
- 1.3.5. Neuživatelské rozhraní
- 1.3.6. Uživatelské rozhraní
- 1.3.7. A co když...
- 1.4. Postup zkoumání domén
- 1.4.1. Shrnutí možností
- 1.4.2. Běžné chyby
- 1.4.3. Požadavky ASM
- 1.4.4. Řešení v souladu s požadavky
Informační technologie se vyvíjejí závratnou rychlostí, což klade zvýšené nároky jak na běžné uživatele, tak zejména na profesionály v oboru. Jednu úlohu je možné řešit mnoha principielně odlišnými způsoby a v rámci každého z nich je obvykle k dispozici množství různých nástrojů. V průběhu vývoje obchodních aplikací je proto nutné činit zásadní rozhodnutí při volbě používaných technologií a správnost těchto rozhodnutí je mnohdy kriticky důležitá pro úspěch aplikace nyní a ještě více pro její úspěch v budoucnu. Situace je ještě o něco nepřehlednější proto, že prakticky všechna řešení jsou alespoň někým (minimálně dodavatelem) prezentována jako nejlepší.
Dokument má formu jakéhosi širokého přehledu běžných (včetně nevhodných) a perspektivních (včetně méně běžných) standardů a technologií souvisejících s obchodními aplikacemi. V tomto směru ovšem samozřejmě nebudu vyčerpávající - na to by nestačilo ani tisíc stránek. Pokusím se být téměř vyčerpávající co do principielně odlišných tříd řešení. Znamená to tedy, že pokud doporučím nějaký nástroj či technologii, nemusí být nutně ve své oblasti nejlepší, ale pouze to, že je principielně vyhovující, tedy že pomůže v realizaci požadavků ASM. Narazíte-li při svém zkoumání na lepší řešení, prosím dejte mi vědět, rád dokument doplním či opravím.
Cílem je zmapovat tuto nepřehlednou oblast a přitom
analyzovat principiální nedostatky v architektuře zejména obchodních aplikací
stanovit obecné zásady správné architektury
najít vhodné standardy a nástroje pro jejich realizaci
Po prostudování byste měli být také o něco více schopni sami, sledováním stanovaných principů, odlišit řešení, která se za dobrá prohlašují od těch, která jimi skutečně jsou.
Cílem této práce například není:
analyzovat principiální nedostatky speciálních vědeckých aplikací, aplikací nutně pevně svázaných s hardwarem (operačního systému), her apod.
analyzovat jiné než principiální nedostatky obchodních aplikací, tedy například jejich rychlost
být úplným, vyčerpávajícím souhrnem standardů či nástrojů v nějaké oblasti
detailně popisovat nějaký standard či nástroj
Tento dokument se také nazabývá vývojovým procesem - tedy nezkoumá jednotlivé kroky ve vývoji aplikace, jejich návaznosti, souvislosti apod. Proto, prosím, nezaměňujte ASM (=architecture subordinate to model) s MDA (=model-driven architecture), standardem konzorcia ODMG, který se zabývá právě vývojovým procesem a zejména modelováním. MDA stejně jako ASM usiluje o flexibilitu, snadnou změnu, nezávislost apod., ale řeší ji v jiné rovině a tedy definuje pojmy model i architektura jinak. Obě metodologie se mohou velice vhodně doplnit, ale abych dokument ještě více nekomplikoval, přímo v něm o MDA i procesu decentně mlčím. Základní informace o tomto námětu včetně souvislosti s ASM najdete v příloze.
Možná se ptáte sami sebe, zda máte číst dál. Pokud se ztotožníte alespoň trochu s jednou z těchto rolí, číst byste měli. BA je zde zkratkou "business application".
- manažer BA
Kladete si otázky: Jak vytvořit BA, kterou by bylo možné snadno spravovat? Jak ji vytvořit rychle, ale zejména dobře? Jaké standardy a technologie přitom zvolit? Jak využít maximum z vhodných nástrojů, ale příliš se na žádný nevázat? Jak vydělat teď a jak vydělávat v budoucnu? Jak neodradit zákazníka, který toho nebezpečně mnoho ví? A co když se mu dostal do rukou tento dokument?
- vývojář BA
Ptáte se, jakých zásad se máte držet, když chcete, aby vám práce rychle ubíhala, abyste nemusel neustále něco záplatovat, abyste měl o své části aplikace dostatečný přehled, ale přitom se dokázal soustředit na právě řešený problém, abyste se ve svém (i cizím) kódu vyznal... Možná nebudete mít tolik prostoru k naplnění zde uvedených zásad, ale i pro vás bude dokument zajímavý a podnětný.
- zadavatel BA
Právě hledáte dodavatele informačního systému pro vaše potřeby. Nebude to zanedbatelná investice, proto chcete, aby tomu odpovídal i výsledek. Chcete robustní, kvalitní systém, který bude sloužit vám a ne naopak. Chcete, aby bylo možné (snadné) reflektovat změny ve vaší společnosti, v zákonech, postupech... Chcete první výsledky co nejdříve, ale ne na úkor kvality. Chcete, aby systém pracoval „v malém“, ale aby mohl do budoucna růst (škálovatelnost). Chcete toho ještě mnohem víc a všichni vám slibují všechno.
Ještě jedna připomínka: pokud mluvím o business application, obchodní aplikaci, informačním systému, is a někdy prostě jen o aplikaci, neomezuji ji nijak co do rozsahu či typu zpracovávaných dat - je jí míněno téměř cokoliv, co shromažďuje a zpracovává uživatelská data, komunikuje s uživateli a jinými systémy.
Materiál je to poměrně „hutný“- na málo stránkách je informací tolik, že možná budete mít pocit, že se v nich trochu ztrácíte. V takové situaci se zkuste alespoň v mysli vrátit k celkovému pohledu na zkoumaný is a k tomu, jaké uplatnění v něm má čtená pasáž textu. Případné pojmy a zmiňované technologie se snažím alespoň v kostce přiblížit a pro čtení snad tedy nejsou třeba žádné specielní znalosti, snad jen běžné vzdělání či povědomí v oblasti it. Pokud vám nějaký pojem nebude jasný, zkuste si část přečíst ještě jednou. Pokud to nepomůže, můžete jej jej ignorovat, protože nejspíše není nezbytný pro pochopení základní myšlenky anebo se pustit do výzkumu na vlastní pěst.
Práce je rozdělena do kapitol, ovšem logicky její členění odpovídá možná spíše tabulce - jakmile vymezím domény řešení, budu se snažit u každé zvlášť postupovat dle názvů kapitol: Shrnutí běžných řešení, jejich chyby, požadavky správného řešení, příklady vhodných nástrojů a standardů. Věřím, že vám takové uspořádání pomůže v orientaci.
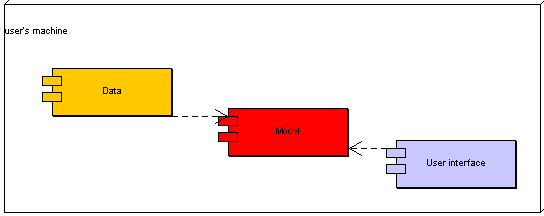
Prosím prohlédněte si níže uvedený obrázek. Znázorňuje obecný is tak, jak ho zde chápeme. Jádrem je model, komunikaci s uživateli zajišťuje uživatelské rozhraní, data jsou ukládána do úložiště a vstupy a výstupy jakéhokoliv jiného charakteru než „uživatelského“obsluhuje „neinteraktivní rozhraní“. Celá aplikace běží v nějakém prostředí. Níže stručně popíšu jednotlivé části a v dalších kapitolách se budeme zabývat každou zvlášť.
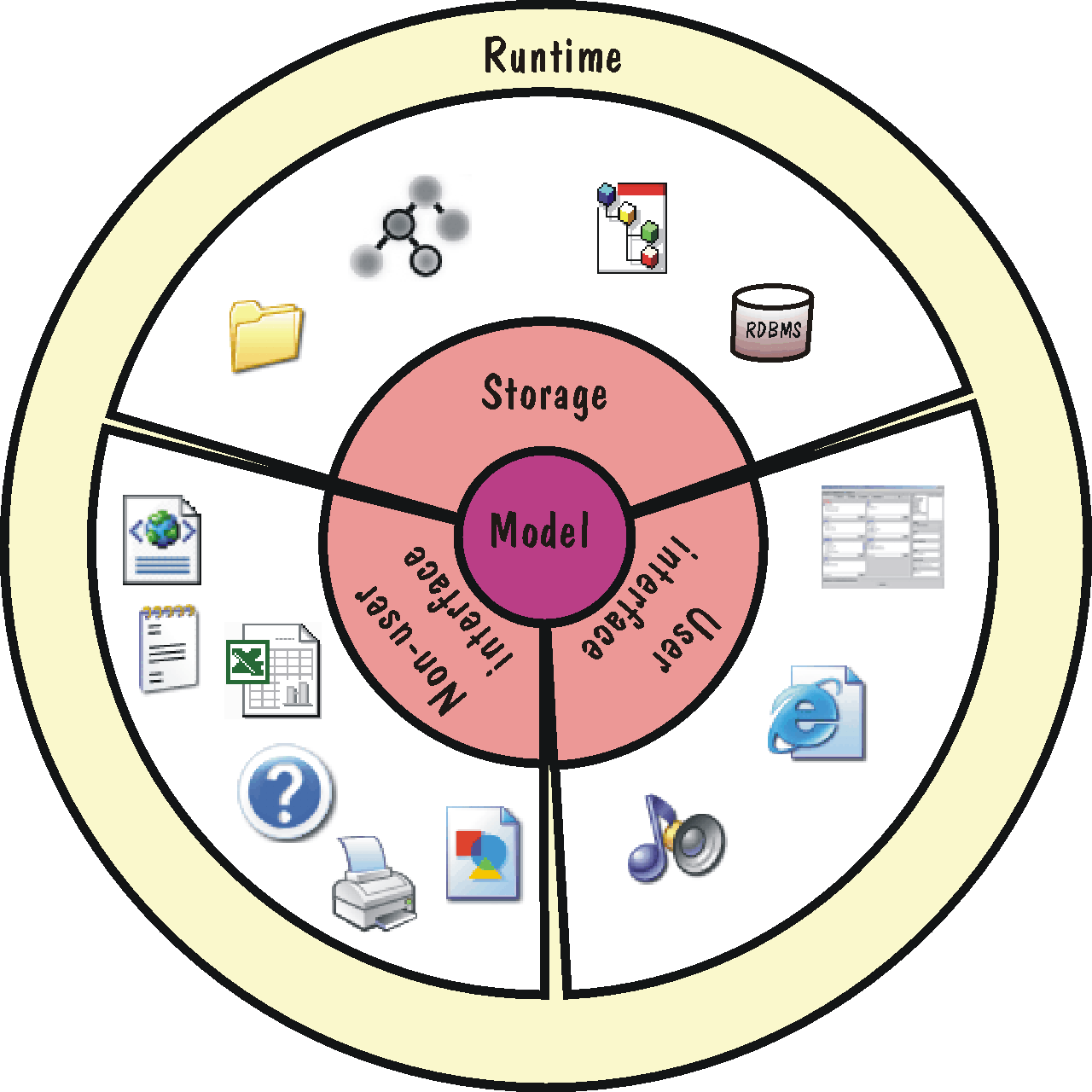
 |
Modelem zde rozumím jádro is, jeho část, která určuje jaká data se mají zpracovávat, jaké jsou závislosti mezi daty, typově jaké výstupy by měly být generovány ap. Není to tedy pouze datový model, ale i aplikační logika. A také to není pouhý návrh, ale i příslušná implementace. V příloze B – „Proces vývoje aplikace“ uvidíme, že dělící čára mezi těmito způsoby chápání modelu je čím dál tím méně zřetelná. V této příloze se také trochu dotkneme některých prostředků k dosažení dobrého vnitřního návrhu modelu, ale ani tam se nebudu zabývat vlastním modelováním - k tomuto tématu se dočtete jinde 2 – „Model“.
 |
Platforma je vše, na čem aplikace poběží. Řadím sem veškeré technické vybavení, které je nutné k provozu operačního systému a is (hardware), operační systém a další low-level software, například síťový. Blíže viz 3 – „Platforma“.
 |
Pod pojem infrastruktura patří:
logické rozmístění funkčních celků is v rámci distribuovaného prostředí
případná síťová architektura, pokud ovlivňuje logické rozmístění objektů
Blíže viz 4 – „Infrastruktura“.
 |
Takové (téměř jistě softwarové) vybavení, které dokáže datům dodat trvalosti (perzistence). Nejběžnější implementací úložiště je nějaká forma databázového systému. Blíže viz 5 – „Úložiště“.
 |
Jsou to rozličné kanály z a do aplikace, které nemůžeme označit jako uživatelské rozhraní a ani jako kanál k úložišti - zahrnuje rozličné:
výstupy, tedy např. tisk, různé prezentace, logy, data pro jiné is apod.
vstupy, tedy zejména vstupy z jiných („cizích“) is.
Blíže viz 6 – „Neinteraktivní rozhraní“.
 |
Zastřešuje vše, co z fungujícího is „vidí“ většina užvatelů - nejčastěji konkrétní programové obrazovky pro zadávání dat, ovládání, správu... Blíže viz 7 – „Uživatelské rozhraní“.
Stručně jsme vymezili, které oblasti nás zajímají. Pokud vašemu systému některá část chybí (například nepotřebujete komunikovat s uživateli), nezoufejte - jednoduše ji v dokumentu přeskočte. Pokud vás například zajímá pouze jak vyřešit ukládání dat, po dočtení této úvodní kapitoly můžete přímo přejít k „Úložišti“. Pokud naopak nějakou část v obrázku marně hledáte, pak
se mi nepodařilo vysvětlit dostatečně jasně oblasti zájmu tohoto dokumentu
vaše aplikace je dostatečně nestandardní, aby ji nebylo možné výše uvedeným způsobem zobecnit
na něco jsem zapomněl. V takovém případě se neváhejte ozvat, chybu rád napravím.
Ovšem věřím, že i v takovém případě zde naleznete něco užitečného.
V této části se pokouším shrnout běžné přístupy k jednotlivým doménám. Pokud je hodnotím, zkoumám je samostatně nebo ve vzájemném srovnání, ale neposuzuji je ve vztahu k ASM. K tomu bude prostor dále. Pouze u problémů, které to dle mého posouzení vyžadovaly, jsem se pustil do trochu větší šíře, ale nikdy příliš do hloubky.
V této části se pokouším specifikovat dle mého názoru principiální problémy běžných řešení.
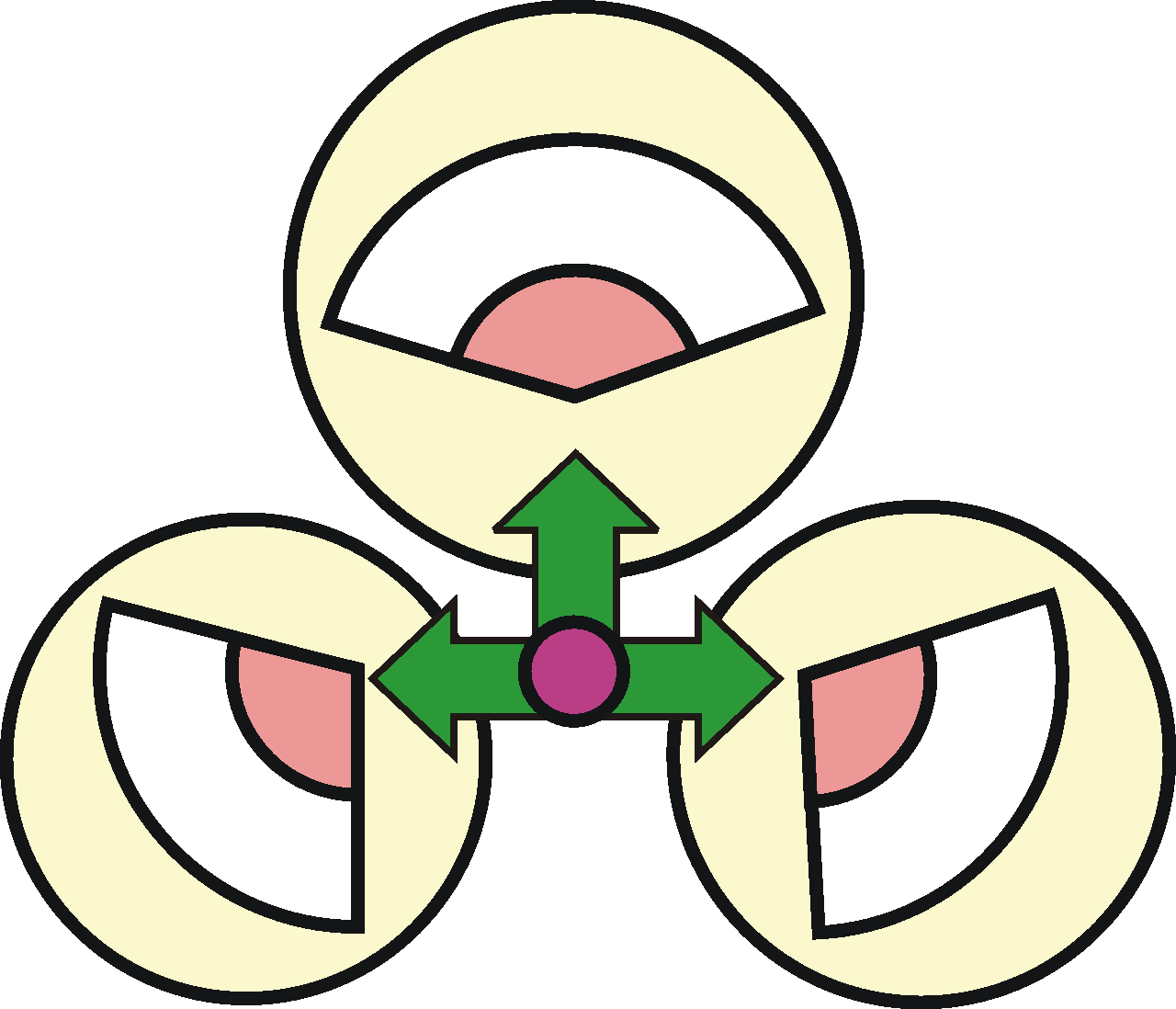
V takto nazvané části můžete hledat odpověď na otázku: Jak by to tedy být mělo? Základní myšlenkou ASM je „princip obalu“, který můžeme shrnout asi takto: Klíčový je model - vše ostatní je obal. Tak snadno, jako můžeme zabalit například boty, tak snadno bychom měli být schopni „obalit“ model aplikace. Tak snadno, jako přehodíme boty do jiné krabice a krabici vložíme do nákupní tašky, bychom měli být schopni měnit části architekturálního obalu aplikací. Jakých okamžitých i odvozených přínosů uplatněním této zásady v celé aplikaci dosáhnete, můžete sledovat na obrázku:
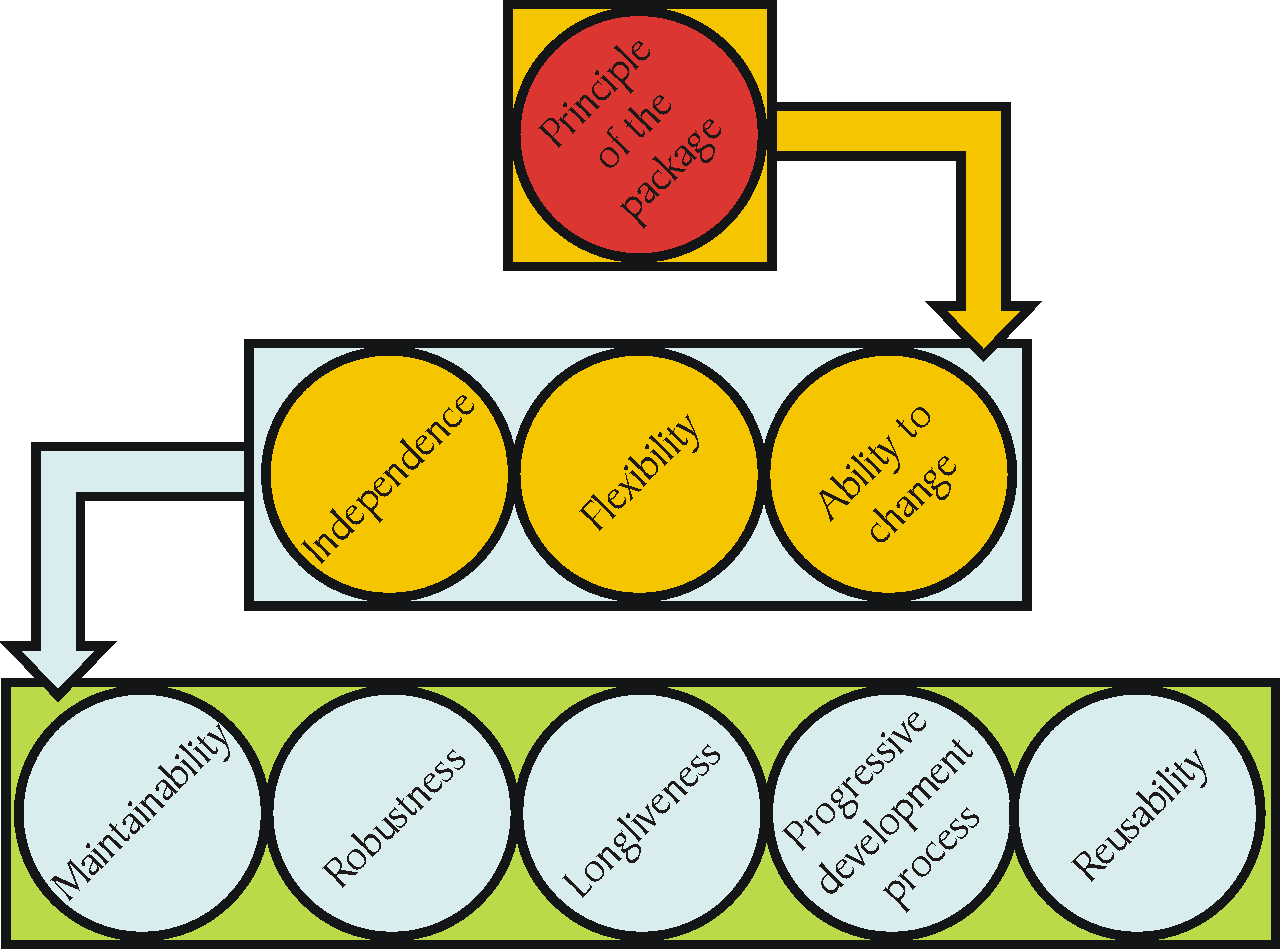
Žlutě jsou zachyceny primární cíle ASM (výsledky uplatnění klíčového principu), tedy:
nezávislost
flexibilita
změna
V modrých kolečkách jsou příklady druhotných přínosů, tedy snadná údržba, robustnost, trvalá hodnota, vpřed postupující vývoj, znovupoužitelnost. U každé popisované části is zkusím formulovat požadavek ASM, tedy stručný souhrn vlastností, které aplikace vytvořená dle ASM musí či nesmí mít a vlastností, které by měla, případně neměla obsahovat, aby byla vytvořena v souladu s principem obalu a výše uvedených cílů mohla dosáhnout. Aplikace která tyto požadavky splní, může být označena jako „aplikace s architekturou podřízenou modelu“ nebo zkráceně ASM aplikace.
Nejlepší kritika je taková, která nabízí alternativu či řešení. U problémů, které dle mého posouzení nevyžadují další zkoumání, je přímo uvedeno co použít a proč to doporučuji. Tam, kde jsou konkrétní možnosti řešení nejednoznačné či neznámé, je provedeno stručné porovnání možných řešení (které již vyhovují ASM požadavkům) a pokud je to možné, některé z nich na závěr doporučeno.
Není vhodné svázat systém s uzavřeným proprietárním řešením, u kterého konec podpory ze strany výrobce znamená skutečně definitivní konec podpory. Kde je to možné, jsou proto upřednostněna open-source řešení.
- 2.1. Shrnutí možností
- 2.2. Běžné chyby
- 2.2.1. Strukturální programování
- 2.2.2. Relační model
- 2.2.3. Model založený na XML
- 2.2.4. Objektový model
- 2.3. Požadavky ASM
- 2.3.1. Požadavek
- 2.4. Řešení v souladu s požadavky
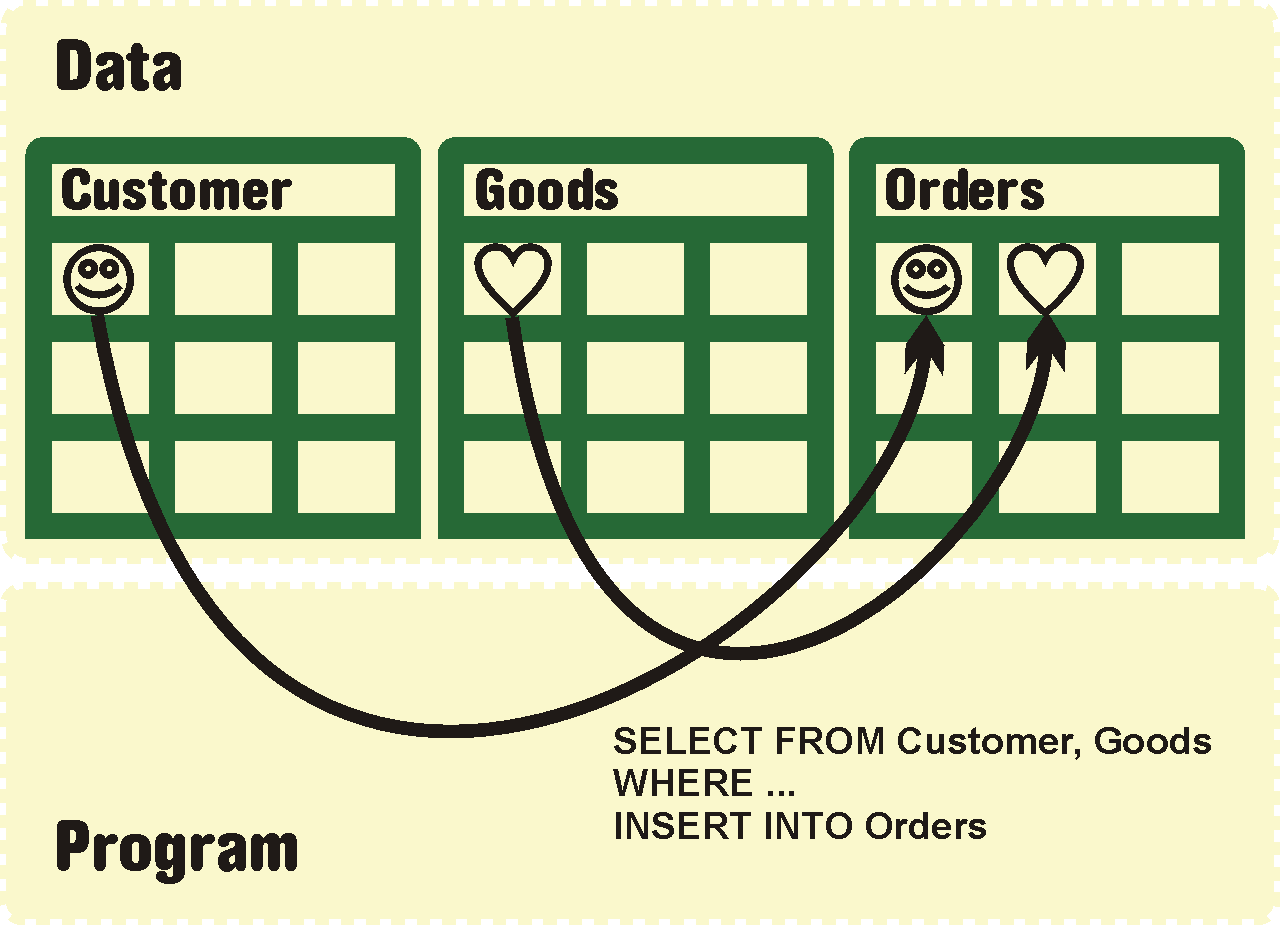
V našem pojetí model znamená strukturu dat a množinu procesů aplikace. Připadají v úvahu dvě koncepčně odlišné možnosti:
Data jsou shromážděna odděleně, procesy se provádějí „nad nimi“. Tento přístup je charakteristický například pro relační databáze v kombinaci se strukturálním (nebo též procedurálním) programováním.
Data a procesy jsou vhodně kombinovány, jsou pohromadě. Tento přístup je charakteristický pro objektově orientované programování.
Tzv. relační model je charakteristický tím, že veškerá logika systému je vyjádřitelná vztahem mezi daty. Procesy, které nad těmito daty pracují, mají sloužit pouze k vytěžení, uložení a změně těchto dat a občas provést nějaké složitější operace nad těmito daty. Pro zachycení vztahu mezi daty slouží tzv. ERD diagram. Dvě a více tabulek se mezi sebou provazují pomocí klíčů (existuje několik typů vazeb). Důležité však je, že znalost ERD diagramu systému znamená znalost 90 % informací o systému. [zoop, str.40]
Důležité na způsobu programování, označovaném jako strukturální je to, že pokud hovoříme o činnosti v programu, máme tím na mysli nějakou funkci, resp. proceduru, v systému vytvořenou, kterou můžeme volat se vstupními parametry a získat výstupní parametry. Celý tok programu je vyjádřitelný právě pomocí takovýchto funkcí a tok činnosti je dán jejich složením- tedy strukturou funkcí a procedur - odtud název strukturální programování. Takový program neobsahuje žádné objekty ve smyslu jak jsou popsány níže. [zoop, str.19]
Z hlediska oddělenosti dat od operací by do této kategorie patřil rovněž model založený na XML, jehož základním stavebním kamenem nejsou tabulky, ale spíše strom.
Objekt je uzavřená struktura v programu, která splňuje určité charakteristiky. V první řadě obsahuje vnitřní paměť - ta je zvnějšku objektu nepřístupná. Je jeho soukromou záležitostí, co si objekt pamatuje a jak. Součástí vnitřní paměti mohou být další objekty. Objekt dále obsahuje metody, posloupnosti kódu programu, které vykonávají nějakou činnost nad vnitřní pamětí objektu (a ideálně pouze nad ní). Můžeme si představit, že metoda objektu je jedinou možností jak zpracovat vnitřní paměť objektu. [zoop, str.10]
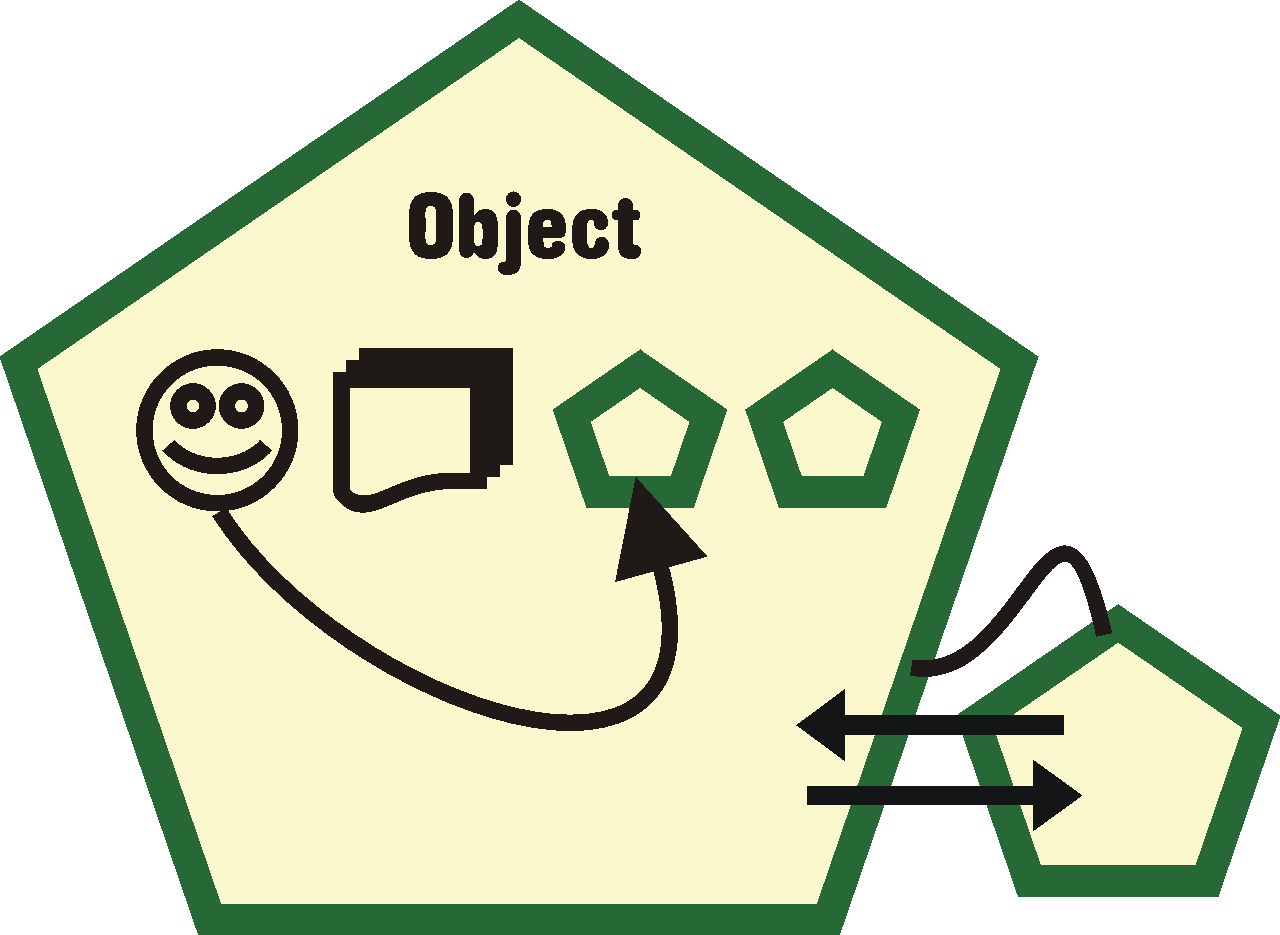
- Zapouzdření
Objekty by měly být co nejvíce podobné „programátorské černé skříňce“. Tedy maximum toho, co objekt ví ale i co umí skrýt před okolím a naopak zpřístupnit pouze nejnutnější minimum. Opět je soukromou záležitostí objektu co si uvnitř dělá, pokud jeho veřejné rozhraní pracuje správně. Tato uzavřenost (encapsulating nebo též zapouzdření) je jednou ze základních charakteristik objektů.
- Dědičnost
Dalším výrazným rysem objektově orientovaného přístupu je snaha vyhnout se opakovanému programování věcí, které již byly jednou vtěleny do objektů, tedy dědičnost, inheritance. Ta umožňuje vytvářet specifičtější objekty podle vzoru jiných objektů a přidat nové schopnosti, případně pozměnit zděděné. [tp]
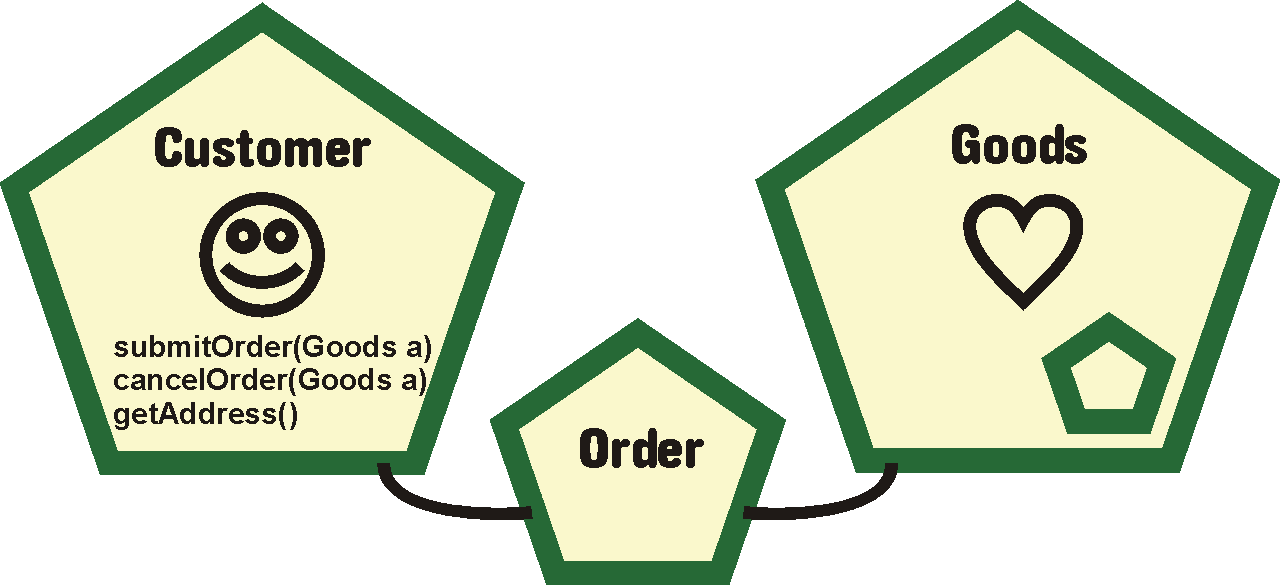
Takto vypadá výše uvedený příklad převedený do podoby, jak jej zachytí objektový model:
Již zavedení strukturálního programování bylo pokrokem oproti předešlému přístupu „řádkového“ programování složeného ze samých odskoků GO TO na návěští. Již při strukturálním programování se objevují určité prvky zapouzdření a to zapouzdření samotných funkcí a procedur při jejich skládání a při jejich strukturovanosti. Z procedurálního kódu je možné sestavovat bohaté knihovny. U strukturálního programování je výhodou, že je možné vnitřní funkci (která skládá vnější funkci) vyměnit, resp. opravit, a vnější složená funkce toto nepocítí. Když tedy voláme vnější funkci, potom nás nezajímá, jak je vnitřně strukturovaná. A právě v tomto ohledu lze hovořit o určité uzavřenosti nebo zapouzdření složených procesů, ale nikoliv o uzavřenosti nebo zapouzdření dat-proměnných. [zoop, str.19] Strukturální přístup selhává při potřebě dodatečných dramatických zásahů do systému. Ty nemusí být potřeba jen z důvodu chyb při úvodní analýze, ale mohou si je vynutit i skutečnosti, které vejdou ve známost až při přirozeném vývoji systému a nelze je na začátku předvídat. Za problém lze tedy potom obecně označit stupeň flexibility, který je dán tomu kterému modelu. Pokud jsou totiž objeveny chyby anebo nastane výše uvedená žádost o změnu systému a tento není napsán flexibilně, potom je vše ostatní už jedno, protože není co a hlavně není jak opravovat. Zkušenosti potvrzují, že pokud se jedná o jen trochu složitější systém, tak představa, že na základě „jedné analýzy“ navrhnu „jeden dobrý systém“, je nereálná. Na prvním místě musí být flexibilita a až potom bezchybnost návrhu. [zoop, str.39]
Kde je příčina problému strukturovaného programování? Abychom na tuto otázku mohli odpovědět, musíme si uvědomit, že celá složitost úkolů, které jste schopni vyřešit je přímo úměrná druhu a kvalitě abstrakce. Pod „druhem“ si lze představit větu: „Co vlastně zobecňujete?“ Assembler je malou abstrakcí podkladového počítače. Celá řada procedurálních jazyků, jež se objevily posléze je abstrakcí assembleru. Všechny tyto jazyky jsou jeho zdokonalením, ale jejich primární abstrakce i nadále od programátora vyžaduje, aby spíše než v souvislostech úkolu, který se snaží vyřešit, uvažoval v souvislostech uspořádání počítače. Programátor musí nastavit asociaci mezi modelem určitého stroje a modelem úkolu, který si žádá vyřešení. K tomuto mapování je třeba vyvinout značné úsilí a vznikající programy jsou velmi složité a jejich údržba velmi náročná.. [myslime, str.39]
Datový model navržený pomocí metodologie zvené strukturální analýza má několik nesporných výhod. Například:
Existuje solidně propracovaná teorie strukturální analýzy.
Databáze jsou podepřeny kvalitní relační teorií. Mocný jazyk SQL je i přes implementační odlišnosti standardní.
Existují silné CASE nástroje podporující tvorbu datového modelu.
Z kterékoliv části programu je možné vidět celý systém najednou, „z ptačí perspektivy“- data jsou všude přístupná, díky tomu nový požadavek zapadající do modelu je „pouze jeden SELECT navíc“.
Ovšem systémy založené na relačním modelu trpí podobnou chybou jako strukturální programování: Zásahy v modelu značně ovlivní program a znesnadňují tak údržbu a vývoj celé aplikace. Co se stane, když máme bohatou košatou databázi a v jedné tabulce změním jednu definici sloupce, anebo dokonce když změním na základě změny požadavků celou vazbu? Co když požadavky na systém natolik narostou, že počty tabulek začínají přerůstat rozumnou mez a jdou do počtu až několika stovek a poté provedu změnu v několika z nich? Je to jednoduché - procesy začnou „padat“. Systém se stane neudržitelným a jakýkoliv zásah do něj způsobí neustálé problémy pracovníkům z jiných částí týmu, kteří nic netuší a všichni se jenom rozčilují, proč databáze najednou nefunguje. Navíc, a to je horší, nelze mnohdy ani určit, kterých procesů se změny dotknou. Musíte, ať už s podporou programovacího prostředku anebo čistě ručně, projít všechny příkazy SQL databáze, které tabulky, vazby atd. používají, a měnit, měnit, měnit... A protože máte vytvořit systém dost složitý, zákonitě se dostane do kruhu - oprava jedné skupiny tabulek s sebou přináší další opravy jiných tabulek a procesů atd. a systém se stane krajně nestabilním. [zoop, str.41-42] A proč to všechno nastane? Může za to „výhoda veřejnosti“- procesy počítají s datovou strukturou tabulek, kterou jste publikovali všem.
U větších projektů hrozí podobné nebezpečí jako u relačních modelů, způsobené přílišnou veřejností dat i jejich schémat.
Objektový model sám o sobě v drtivé většině případů chybou není. Chyby ovšem mohou vzniknout ve vývojovém procesu. Zdrojů k UML (modelovací jazyk pro objektové modely), k modelování a i k vývojovému procesu obecně je poměrně mnoho a detaily v tomto směru nejsou předmětem zájmu tohoto dokumentu, ale přesto - něco málo zejména k trendům v této oblasti se možná dozvíte v B – „Proces vývoje aplikace“.
Pokud nemáte skutečně závažný důvod pro jiný přístup, is založte na objektovém modelu. Tím se zúží volba programovacího jazyka na ty objektově orientované. Ovšem dříve než se pustíte do programování, věnujte dostatek času analýze a návrhu. Samotný objektový model sám o sobě žádnou flexibilitu nezajistí, pouze nabízí prostředky, kterými je možné „udělat to dobře“. Nejběžnějsí programovací jazyky z této kategorie najdete shrnuty v 3.1.1 – „Procedurální“.
Věta „pokud nemáte...“ v úvodu předchozího odstavce není samoúčelná, protože v některých případech může být vhodný jiný model. Už jsme se zmínili o stromovém (XML) modelu. Ten rozhodně nemůžeme jednoznačně zatratit, a někdy je naopak ideální. Příkladem mohou být systémy pro správu dokumentů (document-management). V takovém případě můžete uvažovat o vhodné kombinaci s objektovým modelem.
Nemůžeme zatratit též různé specifické modely - viz 3.1.2 – „Logické, deklarativní, pravidlové apod.“. I když dodejme, že i některé z těchto speciálních jazků se snaží nabídnout rysy objektového programování, a tak jdou správným směrem.
Prosím ale, zapomeňte na čistě strukturální programování. Příslušné jazyky se vydaly správným směrem, ale nedošly dost daleko a zůstaly na půli cesty mezi assemblerem a jazyky objektově orientovanými. V dnešní době je můžeme považovat pro účely vyvíjení obchodních aplikací za překonané.
Rovněž, prosím, zapomeňte na relační model jako na všelék a raději vytvořte kvalitní objektový model. Prosím pozor - nezavrhuji zde relační databáze jako takové ani mohutnou relační teorii, pouze nedoporučuji chápat relační model jako jádro aplikace a zároveň nedoporučuji kombinovat SQL s programovým kódem. I přes to jsou RDBMS ověřeným a široce podporovaným standardem pro úložiště - čímž vás nepřímo navádím do jiné kapitoly, tedy 5.1.3 – „Objektově-relační mapování “.
K tomu připojím doporučení pana Amblera pro návrháře datových modelů: [mapping]
Návrháři logických modelů: Ve skutečnosti již nebude třeba logických datových modelů, pouze tam, kde se ještě nezačalo pracovat v souladu se současným trendem a tedy podle zásad OO, a to jen dočasně. Návrháři logických modelů se proto budou muset naučit navrhovat objektové a/nebo fyzické datové modely. Dobrou zprávou je, že mnohé zkušenosti, které jako návrháři logických modelů získali, budou moci využít - schopnost nadhledu, schopnost modelovat, schopnost dodržovat doporučení. Špatnou zprávou ovšem je, že jejich oblíbený modelovací mechanizmus a datové modely již nestačí a byly překonány objektově orientovaným modelováním. Toto doporučení možná není lehké přijmout, ale čím dřive začnete, tím lépe pro vás.
Návrháři fyzických modelů: Ať samozvaní OO guruové říkají co chtějí, fyzické modely jsou stále potřeba. Budete se ale muset naučit navíc mapovat objekty do relačních databází. Dobrou zprávou pro vás je, že po lidech, kteří to dokáží je silná poptávka.
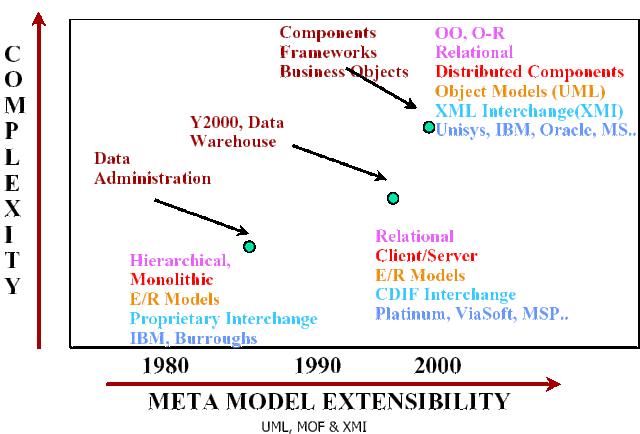
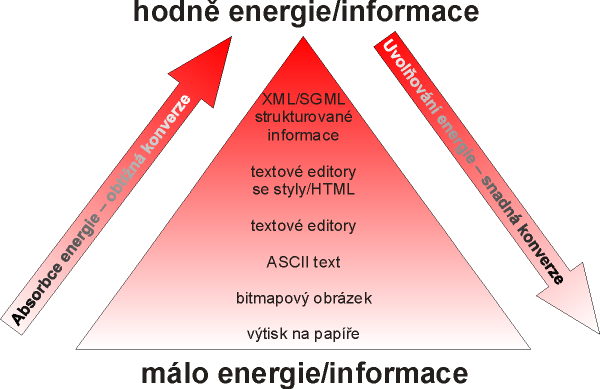
Pro dokreslení uvádím tabulku pokroku v oblasti architektur. Půjčil jsem si ji z [metadata]. Ukazuje postupný odklon od relačních modelů a strukturovaného programování jako očekávatelný vývoj v architektuře.
- 3.1. Shrnutí možností
- 3.1.1. Procedurální
- 3.1.2. Logické, deklarativní, pravidlové apod.
- 3.2. Běžné chyby
- 3.3. Požadavky ASM
- 3.3.1. Požadavek
- 3.4. Řešení v souladu s požadavky
- 3.4.1. Jazyky kompilované
- 3.4.2. Jazyky interpretované
- 3.4.3. Jazyky interpretované s bytekompilací
Čím je dána platforma, na které vaše aplikace poběží? Zejména použitým programovacím jazykem, konkrétně dostupností kompilátoru či interpreteru na různých platformách, ale i dostupností použitých knihoven, závislostí na proprietárních systémech (třeba databázi, uživatelském rozhraní, souborovém systému apod.). Zmiňme nyní krátce některé běžně používané programovací jazyky:
- C++
C++ je kompilovaný, hojně využívaný v praxi, vyvinul se ze strukturovaného předchůdce jazyka C zejména přidáním objektové orientovanosti.
- Object Pascal
Object Pascal se vyvinul ze strukturovaného předchůdce, jazyka Pascal zejména přidáním objektové orientovanosti. Stejně jako C je kompilovaný. Podporuje jej především firma Borland, která prodává odpovídající vývojová prostředí Delphi a Kylix.
- Smalltalk
Smalltalk je poměrně nový interpretovaný kvalitně navržený objektově orientovaný programovací jazyk.
- Java
Java je rovněž docela nový čistě objektově orientovaný programovací jazyk založený na interpretaci bytekódu. Má silnou podporu ze strany firem, standardizačních skupin, open-source skupin i samostaných vývojářů, k dispozici je ohromné množství technologií, nástrojů a pomůcek, které řeší mnoho běžných i méně běžných programátorských úkolů.
Pravděpodobně je nepoužijete pro vytvoření celé aplikace, ale mohou dobře posloužit v oblastech umělé inteligence, tedy tam, kde klasické procedurální jazyky nestačí. Mluvím o oblastech jako dolování informací , rozpoznávání tvarů , práce s lidskou řečí , zpracovávání nejasných a neúplných údajů - to všechno může být součástí obchodní aplikace.
- LISP
LISP (LISt Processing, zpracování seznamů) je interpretovaný, plně strukturovaný jazyk, v zásadě se skládá pouze ze seznamů volání funkcí. To mu dodává neobvyklou flexibilitu.
- Scheme
Scheme je mnohaúčelový programovací jazyk vyšší úrovně, podporuje operace se strukturovanými daty (řetězci, seznamy, vektory) stejně jako s primitivními typy. Často je spojován se symbolickým programováním, ale jeho bohatá nabídka datových typů a flexibilní struktury pro práci s nimi z něj dělá skutečně univerzální jazyk. Důkazem je, že existují textové editory, kompilátory, operační systémy, grafické knihovny, expertní systémy, výpočetní aplikace, aplikace pro finanční analýzy a snad každý další představitelný typ aplikace. A začít se Scheme není nijak obtížné! [scheme]
- Prolog
Prolog je jazyk pro programování symbolických výpočtů. Jeho název, odvozený ze slov PROgramování v LOGice, naznačuje, že jazyk vychází z principů matematické logiky. Od počátku byl Prolog využíván při zpracování přirozeného jazyka (francouštiny) a pro symbolické výpočty v různých oblastech umělé inteligence. Používá se v databázových a expertních systémech, při počítačové podpoře specializovaných činností, např. při projektování (CAD) nebo výuce (CAI), i v klasických úlohách symbolických výpočtů, jako je návrh a konstrukce překladačů, a to nejen jako prostředek vhodný pro reprezentaci a zpracování znalostí, ale i jako nástroj pro řešení úloh.
- CLIPS
CLIPS je nástroj pro tvorbu expertních systémů vyvinutý skupinou Software Technology Branch (STB) v NASA. Nyní je používán mnoha tisíci lidmi na celém světě. V CLIPSu existují 3 způsoby, jak reprezentovat poznatky: pravidly - jsou určena k heuristickým poznatkům založeným na zkušenostech, definování funkcí (deffunctions) a generic function - jsou primárně určeny pro procedurální poznatky, objektově orientované programování - také je určeno primárně pro procedurální poznatky. Program lze sestavit použitím jen pravidel, jen objektů nebo kombinací objektů a pravidel. CLIPS byl také navržen pro plnou integraci s jinými jazyky. [clips]
Většina současných programů je vytvářena s pevně stanovenou třídou počítačů a pevně stanoveným operačním systémem nebo třídou operačních systémů, na kterých budou fungovat. Takové řešení je zejména z dlouhodobého hlediska nešťastné - dáváte tím budoucnost aplikace do rukou dodavatele používané platformy. Připojím všeobecnou filozofii návrhu pana Amblera (Scott’s General Design Philosophy ): [mapping]
Proprietární řešení vás vždy poškodí: Stále zdůrazňuji: Opravdu přemýšlejte, než přijmete proprietární technologii. Ano, vždy jsou nějaké výkonostní důvody, a často hraje roli snadnost vývoje, ale nikdy nezapomeňte, že vás musí zajímat rovněž „drobnosti“ jako přenositelnost, spolehlivost, škálovatelnost, rozšiřitelnost a spravovatelnost. Už jsem viděl mnoho společností, které se dostaly do vážných problémů, když použily proprietární vlastnosti, které je svásaly s technologiemi, které se v budoucnu prokázaly jako nedostatečné.
Co když dodavatel operačního systému zkrachuje? Co když vybraná platforma postupně přestane vyhovovat rostoucím nárokům provozovatele aplikace, například z hlediska výkonu či bezpečnosti, zatímco jiná (nová, lepší, rychlejší, bezpečnější...) by vyhovovala? A proč by měl být uživatel vaší aplikace nucen učit se pracovat s jiným operačním systémem, případně za něj platit, pokud jediné, co potřebuje, je fungující aplikace?
Důležitým pojmem zde je přenositelnost . Tu můžeme sledovat na různých úrovních:
přenositelnost zdrojových kódů
přenositelnost bytekódu
přenositelnost nativního kódu
přenositelnost používaných knihoven
Kromě toho můžeme zkoumat přenositelnost uživatelského rozhraní, dat apod., ale to bude předmětem dalších kapitol.
Pro zodpovězení otázky jaký jazyk je dostatečně přenositelný je třeba poukázat na principielní rozdíly mezi jazyky z hlediska jejich odstínění operačního systému, a to nejen v průběhu programování (to je spíše věc procesu - viz B – „Proces vývoje aplikace“), ale zejména při běhu. Z množiny jazyků nás zajímají pouze tzv. vyšší programovací jazyky, vyšší, protože znamenají značný přínos oproti programování v assembleru, který je z tohoto pohledu „nižší“, tj. blíž hardwaru.
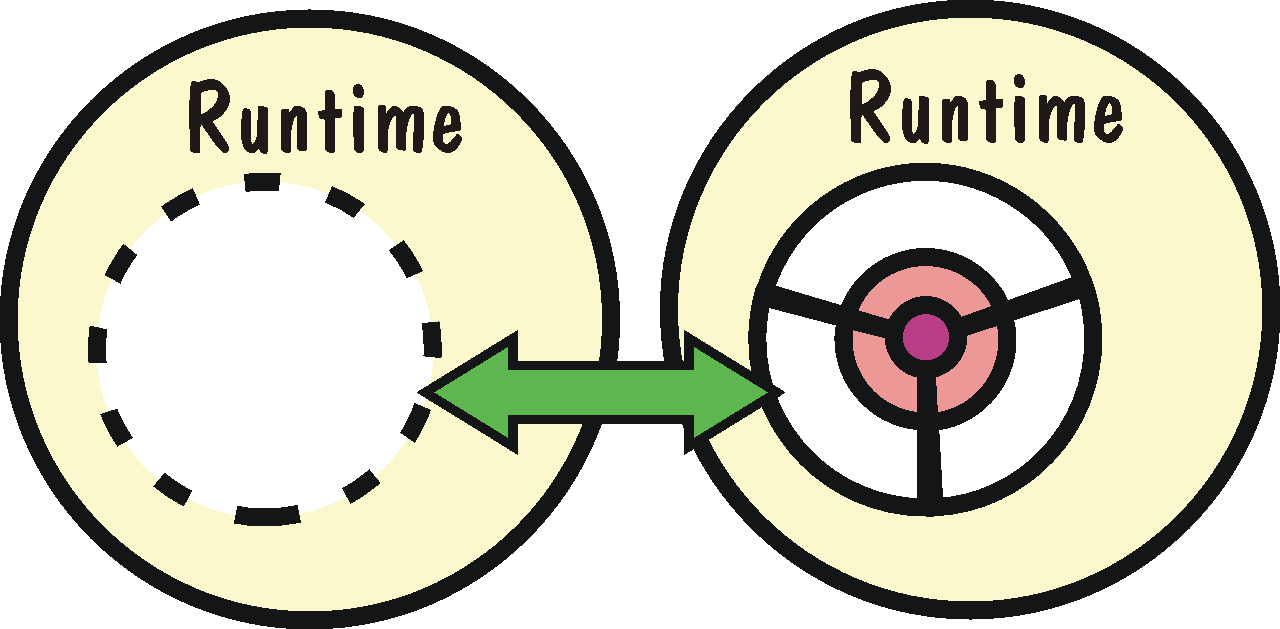
Nejdelší historii mají jazyky kompilované. Jejich výhodou je rychlost výsledných programů - relativně časově náročná kompilace ze zdrojového do nativního kódu, kterému rozumí přímo operační systém proběhne pouze jednou, při běhu se pouze spustí - na obrázcích jsem to znázornil překrývajícími se ovály.
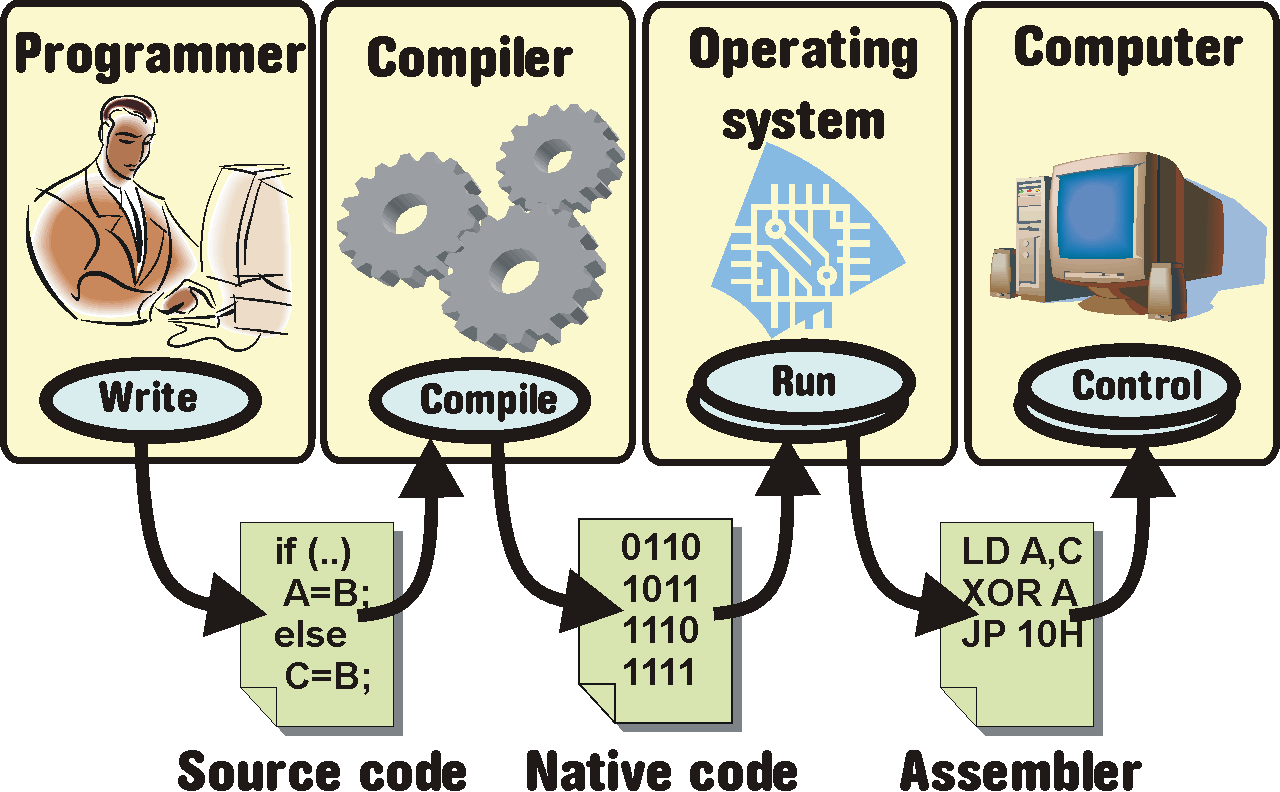
Výsledný program je nativní, tedy nutně nepřenositelný. Řešením by mohlo být (a bývá) použití specifických kompilátorů - a skutečně, kompilátory například jazyka C++ jsou dostupné prakticky pro všechny běžné platformy. V čem je tedy problém, když pomineme „drobnost“, že chcete-li distribuovat aplikaci použitelnou řekněme na 3 platformách, musíte ji pro každou zvlášt kompilovat?
Zejména v knihovnách, které vaše aplikace použije, protože ty musí být také k dispozici pro každou podporovanou platformu. A dokonce ani mnohé standardní knihovny například již zmíněného jazyka C++ se nechovají všude stejně. Z těchto důvodů je zajištění přenositelnosti buď nepříjemné, nebo hodně nepříjemné, nebo (a bohužel velice často) nemožné.
Proto: Vyvarujte se kompilovaných jazyků pokud můžete!
O něco novější jazyky interpretované přinášejí zásadní změnu - vlastní kompilace probíhá až při spuštění programu a nazývá se interpretace. Do této skupiny patří LISP, Scheme, Prolog, ale i většina jazyků označovaných jako skriptovací jazyky, tedy PHP, Perl, Python, Tcl, JavaScript.
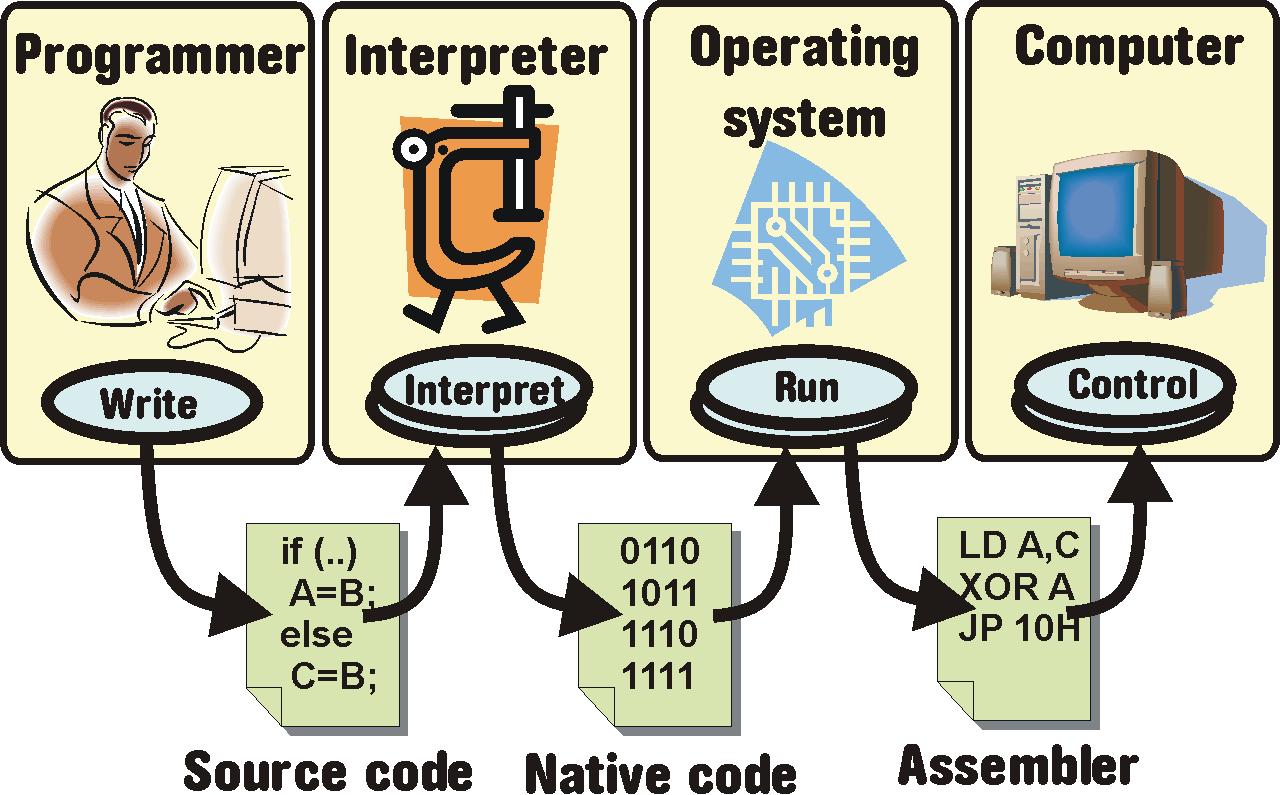
Z hlediska přenositelnosti je to dobré řešení - stačí aby existoval interpret pro každou platformu, která má být podporována. Pokud použijete výhradně přenositelné knihovny (např. v tom samém jazyce), je vše v pořádku. Nebezpečí se skrývá ve schopnosti využívat knihoven neinterpretovaných (a tedy nepřenositelných) jazyků, která je vlastní mnoha interpretovaným jazykům. Použijete-li nativní knihovnu, přenositelnost se rázem zboří. Před volbou interpretovaného jazyka proto prověřte, zda jsou k dispozici přenositelné knihovny ke všemu, co budete využívat.
Nevýhody jsou dvě: Dáváte veřejně k dispozici svůj zdrojový kód, což je chválihodné, ale možná o to nemáte zájem. A dále, program je pomalý - časově náročná kompilace se provádí při každém spuštění.
Jazyky interpretované s bytekompilací jsou další generací jazyků interpretovaných. Rozdělují proces kompilace do dvou fází. Bytekompilátor převede zdrojový kód do tzv. bytekódu, což je operace časově srovnatelná s kompilací do nativní podoby, ale bytekód je platformně nezávislý . Interpretr bytekódu je již nutně platformně závislý, a proto musí existovat pro každou podporovanou platformu.
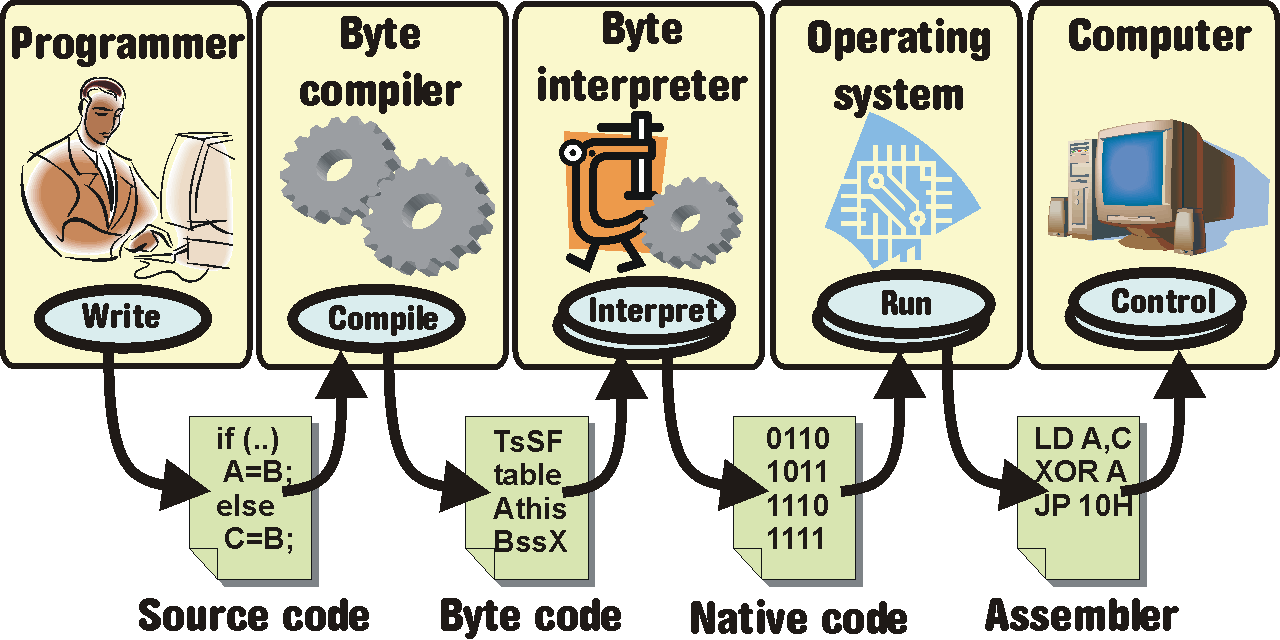
Z hlediska přenositelnosti je to řešení stejně dobré, jako čistá interpretace. Navíc přináší výhodu v podobě vyšší rychlosti běžících aplikací a odpadá nutnost zveřejnit zdrojový kód. Ovšem i zde musíte dbát na to, že využijete pouze přenositelné knihovny. Věřím, že cesta vede právě tudy. Otázkou je, který jazyk konkrétně je nejvhodnější? Odpověď nemůže být naprosto jednoznačná - protože záleží na konkrétních parametrech aplikace. Ale myslím si, že zejména na poli procedurálních objektově orientovaných jazyků je natolik „čisto“, že se poměrně jednoznačný závěr dá učinit.
Hledaný jazyk musí být široce rozšířený, široce podporovaný, dostupné nástroje musí být schopny zajistit vše potřebné bez pevné vazby na cokoliv nativního. Co třeba Smalltalk? Je dobře navržený, výkonný, čistě objektově orientovaný, interpretovaný s bytekompilací, interprety existují pro mnoho platforem... Ovšem trpí právě nedostatkem kvalitních, dostupných knihoven a tento hendikep řeší možností využívat nativní knihovny C a dalších jazyků.
Řešením je Java . Možná má ve srovnání se Smalltalkem nějaké drobné chyby v základní specifikaci, možná trvá o něco déle naučit se s ní pracovat, ale prakticky nehrozí, že byste museli použít cokoliv nativního proto, že v Javě neexistuje vhodný ekvivalent. A existují interprety? Interpret javy se jmenuje Java Virtual Machine (JVM) a existuje skutečně pro cokoliv - PC s jakýmkoliv operačním systémem, handheld, mobilni telefon. Zakladatelem Javy a jejím silným podporovatelem je firma Sun Microsystems. Ale kromě standardní implementace JVM firmou Sun je možné použít i jiné - například IBM JVM nebo některou z open-source. Pokud by Sun z nějakého důvodu přestal Javu podporovat, je dostatečně otevřená na to, aby se jí ujal kdokoliv jiný.
- 4.1. Shrnutí možností
- 4.1.1. Nevrstvená infrastruktura
- 4.1.2. Dvouvrstevná infrastruktura
- 4.1.3. Třívrstevná infrastruktura
- 4.2. Běžné chyby
- 4.3. Požadavky ASM
- 4.3.1. Požadavek
- 4.4. Řešení v souladu s požadavky
Jádrem každé aplikace je její vnitřní logika, struktura dat a procesů nad nimi. To zde označuji jako model. Modelu „slouží“ nějaké úložiště, které dodává datům trvalost a dále uživatelské rozhraní. Tyto funkční celky můžeme chápat v ideálním případě jako uzavřené subsystémy, které navenek komunikují pouze přes konkrétní veřejné rozhraní. Míra takové uzavřenosti udává logickou architekturu a aby se to nepletlo s architekturou ve smyslu ASM, mluvím o ní zde jako o infrastruktuře. Hovoříme-li o fyzické infrastruktuře, máme na mysli nasazení na konkrétních počítačích nebo počítačových systémech a u každého programového subsystému nás zajímá, ve spojení s kterým dalším programovým subsystémem je umístěn na společném počítačovém systému. Nebudu to dále komplikovat - pokračujme pro jednoduchost pouze s druhým pojetím. Připadají v úvahu tyto základní infrastruktury:
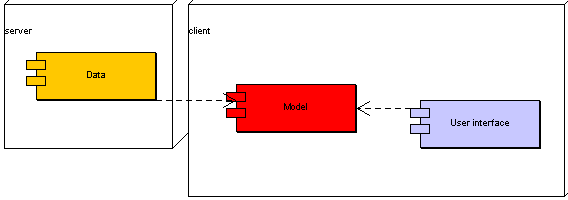
Nejběžněším řešením v jednouživatelském prostředí je nevrstvená infrastruktura. Obvykle všechny části aplikace běží na jednom stroji, výhodou je jednoduchost ve všech směrech - jednoduchá výroba, jednoduché testování, jednoduché nasazení. Není použitelná v distribuovaném prostředí, kde například s jednou databází pracuje více lidí.
Poznámka k obrázku: Je to UML diagram nasazení, krabice znamená hardwarový prostředek, nejspíše počítač.
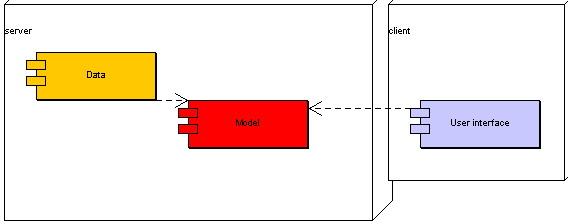
Základní způsob jak umožnit více uživatelům pracovat se sdílenými prostředky (daty případně i procesy), je vytvořit server, který bude tyto prostředky poskytovat klientům, kteří je budou naopak využívat. Data je nutné sdílet prakticky ve všech případech, ale z hlediska umístění aplikační logiky připadají v úvahu dvě možnosti:
Pokud klient obsahuje kromě živatelského rozhraní i aplikační logiku, je to mohutný klient (thick client). Nejčastěji se se připojuje pouze k nějakému úložišti (databázi), aby ukládal a čerpal data.
Klient, který neumí nic jiného, než zprostředkovat uživateli přístup k datům a programové logice tím, že se spojí se serverem je tenký (thin). Takovým klientem může být například prohlížeč internetových stránek („browser“), který žádnou logiku konkrétní aplikace už ze své podstaty obsahovat nemůže.
Je-li každý popisovaný systém maximálně autonomní, je to třívrstevná infrastruktura (three-tier, multilayered):
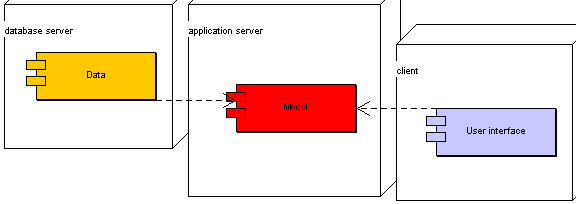
Tato varianta je každopádně nejsložitější, ale přináší mnohé výhody například: [taks]
snadná zaměnitelnost úložiště nebo prezenční vrstvy
snadnější škálovatelnost a z toho plynoucí nižší nároky na hardware
snadnější zapojení starých systémů
lepší odolnost a výkon
Funkční požadavky versus složitost: Distribuované systémy na jedné straně umožňují dostat funkce a data tam, kde jsou potřeba, ale na druhé straně zvyšují složitost. Klient/server systémy mají tendenci být mnohem komplexnější než konvenční desktop architektury. Zmiňme jen pár zdrojů této složitosti: GUI, vrstva aplikačního serveru, heterogenní platformy. Je zřejmé, že je často nutné volit mnoho kompromisů v zájmu snížení složitosti na zvládnutelnou úroveň. [csa4b]
Jinými slovy někdy je chybou zvolit nevrstevnou architekturu, jindy je zase chybou distribuovat. A i pokud je zvolen optimální kompromis mezi protichůdnými požadavky, výsledkem zpravidla je systém, který počítá se zvolenou architekturou a je velice nesnadné přejít k jiné, v případě že si to situace vyžádá. Což je chyba a prohřešek proti základnímu principu ASM a znamená ztrátu flexibility, možnosti změny....
ASM aplikace musí být snadno škálovatelná a to nejlépe z jednoduché desktop aplikace, přes různé klient server modifikace, až po třívrstevný model s aplikačním serverem uprostřed. Druh nasazení by neměl zvyšovat komplexitu objektového modelu a vývojářům by mělo být tak říkajíc jedno, v jak distribuovaném prostředí aplikace poběží.
Objektový model musí být navržen co nejlépe, bez ohledu na finální nasazení. Přechod mezi různými typy distribuce obchodních procesů by měl být realizovatelný pouhou rekonfigurací podpůrných nástrojů, které „obalují“ datový model. Jaké podpůrné nástroje něco podobného dovedou zrealizovat, bude zkoumáno dále.
- 5.1. Shrnutí možností
- 5.1.1. Soubory
- 5.1.2. Objektově orientované databázové systémy
- 5.1.3. Objektově-relační mapování
- 5.1.4. Objektově-relační technologie
- 5.1.5. Mnoharozměrné databáze
- 5.1.6. Stromové struktury
- 5.1.7. Snahy o univerzální přístup
- 5.2. Běžné chyby
- 5.3. Požadavky ASM
- 5.3.1. Požadavek
- 5.4. Řešení v souladu s požadavky
- 5.4.1. Jakarta OJB
Existuje nepřeberně možností, jak ukládat data z aplikace. Data můžeme ukládat jako soubory uvnitř souborového systému, můžeme vytvořit nějaký proprietární atypický ukládací systém, můžeme využít relačních databází, objektových databází, XML databází, LDAP struktur nebo třeba něčeho úplně jiného.
Serializace je nástroj standardní knihovny Javy, tedy je ihned k dispozici. Princip je stručně řečeno takový, že objekt je převeden do binárního datového proudu a nástroje pro zpracování datových proudů ho pak můžou uložit například do souboru. Ze soubou je možné objekt „zrekonstruovat“ do původní podoby.
Pokud nechceme promíchat kód specifický pro tento typ ukládání s vlastní aplikační logikou, musíme vytvořit nějakou vrstvu, která bude ukládání řídit... což znamená vytvořit v zásadě celý databázový systém. Ano, serializace je použitelná pro jednoduché nebo specifické úlohy.
O řešení některých nedostatků standardní serializace se pokouší různé nástroje, které uloží objekt nikoliv v binární podobě, ale do XML a z XML ho umí zpětně zrekonstruovat, tedy provádějí XML mapování. Smyslem této části není doporučovat či zatracovat konkrétní produkty, spíše shrnout asi jaké vlastnosti a funkce je možné v této oblasti očekávat a jaké ne. Z tohoto důvodu ani výčet nástrojů není úplný, spíše jsem se snažil vybrat několik reprezentativních produktů, pokud možno odlišných, abych tak pokryl celou oblast. Zaujme-li Vás některý produkt, bližší informace o něm hledejte, prosím, na příslušných www stránkách.
- JOX
JOX je skupina Java knihoven, které usnadňují přenos dat mezi XML dokumentem a objektem odpovídajícím JavaBeans specifikaci. Můžete chápat JOX jako speciální formu serializace, kde použitým formátem je XML. [jox] JOX je tak snadno použitelný, jako samotná serializace. Výstupní XML soubor má ovšem poměrně plochý formát a nejde příliš (téměř vůbec) přizpůsobovat.
Například představme si třídu Osoba, která má vlastnosti jmeno a datumNarozeni. Hodnoty těchto vlastností můžete načíst z XML souboru. Stejný soubor můžete použít třeba na naplnění vlastností Jmeno a Datum_Narozeni u jiné třídy Zakaznik. [jox]
- KBML - The Koala Bean Markup Language
KBML přístup zvládne mnohem více typů objektů než JOX, ale musíte se uvázat k použití jejich speciálního XML formátu.[jox] Koala XML serializace je nadstavbou standardní serializace. Proces je rozdělen do dvou fází: Všechny objekty jsou serializovány do java.io.ObjectOutputStreama následně převedeny do KOML dokumentu. [kbml] Deserializace probíhá obráceně.
- JAXB
Sun si je rovněž vědom potřeby XML reprezentace objektů. Vybrali si širší řešení, nazvané „data binding“ (JAXB). Toto řešení je mnohem více řízeno daty, protože využívá XML schémata přímo pro generování tříd schopných XML data zpracovávat. Serializace má být nabízena spíše jako vedlejší efekt. Hlavní nevýhoda tohoto využití spočívá v nutnosti opatřit objekty specifickými serializačními a deserializčními metodami (nazvané marshal/unmarshal). [kbml]
Každý ze zmiňovaných nástrojů má své výhody i nevýhody a zejména KBML a JOX jsou skutečně použitelné. Ovšem všechny nástroje řeší opět jenom mechanizmus převodu objektu do nějaké uložitelné formy a nikoliv pokročilejší funkce, které se čekají od systémů označovaných jako databázové.
Objektově orientované systémy (OODBMS) umožňují ukládat objektová data ve tvaru, který je jim přirozený [itl] a jsou tak řešením, které se tak říkajíc na první pohled nabízí, má-li aplikace propracovaný objektový návrh. Již několik let existuje standard vytvořený sdružením Object Database Management Group (ODMG). Definuje komponenty:
objektový model
specifikační jazyky
dotazovací jazyk
vazby do programovacích jazyků
S ODMG je možné vytvářet transakce, přistupovat do databáze více vlákny, znovupoužívat připojení (connection pooling).
Avšak volně nabízené a otevřené OODBMS jsou stále v experimentální fázi vývoje a tak či onak nestabilní, zatímco komerční systémy ohromí svými cenami. Co je ale nejhorší, kromě ODMG existuje hned několik dalších dotazovacích jazyků a žádný není široce podporovaný. [itl]
Na rozdíl od objektově orientovaných, kde jsou data dobře strukturovaná a logicky propojená, jediné co relační databáze (RDBMS ) nabízejí jsou tabulky propojené relacemi. Relační databázové technologie jsou vyspělé - jedny z nejstarších, přitom používané a stále nejpopulárnější ze všech. Přispívá k tomu jejich jednoduchost, efektivita, obecně nižší nákladnost. Existuje i mnoho poměrně pokročilých RDBMS úplně zdarma, například PostgreSQL. [ itl ]
Objektový přístup k tvorbě aplikací pracuje s objekty - strukturami, kombinujícími data a chování, zatímco relační přístup je zaměřený čistě na ukládání dat. Takzvaný impedanční nesoulad (impedance mismatch) vyplyne na povrch, když porovnáme upřednostňované řešení přístupu: U objektového řešení je zvykem objekty procházet tak, jak jsou vystavěny příslušné závislosti, zatímco relační přístup duplikuje data při spojování řádků tabulek. Tento základní rozdíl znesnadňuje kombinaci obou přístupů, ale, přiznejme si, kdy jste naposled použili dvě různé, primárně nesouvisející věci, aniž by to vyžadovalo pár triků? Jedním z tajemství úspěchu při objektově relačním mapování je porozumět oběma přístupům, jejich odlišnostem a na základě tohoto poznání je přimět ke spolupráci. [mapping] Tyto postupy jsou již dnes docela dobře propracované a právě mappingje vhodným úvodem.
V současné době jsou také k dispozici použitelné nástroje, které značně usnadní mapování. Jsou to řešení proprietální, liší se funkcemi, podporovanými formáty popisu mapování, programátorským rozhraním, podporovanými RDBMS a mnoha dalšími vlastnostmi. Na Internetu je k dispozici celá řada srovnání.
Již před lety samozvaní objektoví guruové nabádali, abychom nechodili cestou nesouladu. Ano, objektový přístup je jiný než relační, ale v 99% případů, kdy vývojové prostředí je objektově orientované, úložištěm bude relační databáze. Prosím, smiřte se s tím. [mapping]
Mnoho výrobců databází, např. Oracle používá technologie, které zachovávají přednosti relačních databází a zároven umožnují podle standardu SQL 99 specifikovat uživatelské datové typy (UDT), které logicky odpovídají objektům. Datový model je přímo v databázovém systému objektový a na jeho základě se tvoří jednotlivé tabulky. Toto řešení se principielně neliší od O2R mapování popsaného výše, rozdíl je pouze v přímé podpoře ze strany databáze.
OLAP (On-Line Analytical Processing ) je technologie, která umožňuje pohlížet na data tradiční relační databáze jako na mnoharozměrnou strukturu. Příklad: [itl]

Tento model včetně implementace a nezbytných nástrojů umožňuje rychlé, přirozené zpracovávání dat podél všech rozměrů. Má význam zejména pro velké databáze, kde jsou potřeba postupy označované jako data mining. Součástí mnoharozměrného pohledu mohou být hierarchie a mnoharozměrná aritmetika. OLAP analýza může být implementována nad tradičními (zejména relačními) databázemi, anebo nad speciálním optimalizovaným úložištěm - mnoharozměrnou databází (MDBMS). Jejich cena odpovídá typickému nasazení. [itl]
Stromová datová forma je velmi vhodná pro některá silně strukturovaná data, např. pro dokumenty, hierarchie objektů (třeba uživatelů), reprezentaci plánů apod. Příslušné technologie jsou LDAP, registry, XML databáze a další.
Sami vidíte různorodost existujících řešení perzistence aplikací, z nichž každé má své výhody a nevýhody a to jsem se o mnoha možnostech vůbec nezmínil. Potřeba zastřešit takto různorodé zdroje dat nějakým jednotným rozhraním vyústila v definování konkrétních standardů. Kromě příkladů specifických pro jazyk Java (níže) stojí za zmínku ještě jednou ODMG - viz 5.1.2 – „Objektově orientované databázové systémy“. Tento standard měl původně sloužit jako jednotné rozhraní objektových databází, ale teoreticky (díky svému poměrně univerzálnímu návrhu) by mohl splnit stejnou funkci. Je potřeba mít ovšem na mysli, že použitelný bude ten standard, jemuž se dostane podpory ze strany dodavatelů řešení úložišť.
- JDO
Standard JDO (Java Data Objects) byl definován jako standardní rozhraní mezi objekty Java aplikací a úložišti persistentních dat, nejčastějí relačními databázemi. Snahou bylo oddělit vlastní logiku aplikací od konkrétního způsobu uložení dat, tedy od konkrétní databáze, ať relační či objektové. Použití JDO rozhraní usnadní programátorům práci tím, že se nemusí přímo zabývat konkrétním datovým modelem na úrovni databáze a mohou se plně soustředit na logiku aplikace. V současné době je nejsilnější podpora relačních databází. Významným problémem JDO asi ještě určitou dobu zůstane nedokonalost a různost implementací. Vždyť specifikace a implementace standardu Sun JDO byla zveřejněna teprve v dubnu 2002.
- EJB CMP
EJB (Enterprise JavaBeans) je komponentní architektura pro distribuované aplikace, která může být využita spolu s JDO. Komponenty EJB nabízejí svůj mechanismus pro ukládání dat, a to CMP (Container Managed Persistence). Na rozdíl od JDO je použití CMP omezeno pouze na komponenty EJB, ale zase umožnuje distribuované transakce, přístup k distribuovaným objektům a rovněž nabízí bezpečnostní služby. JDO zase operuje s bohatším, ale zase s lokálním objektovým modelem. Např. objekty CMP musí být z balíků java.util.Set nebo java.util.Collection. Ukazuje se tedy, že JDO a EJB se vhodně doplnují zejména při distribuovaném zpracování. Když komponenty EJB zapouzdří třídy JDO, tak bude možné přistupovat k instancím tříd JDO vzdáleně a přímo.
Jaký typ úložiště zvolit? Otázka to mnohdy není jednoduchá a její zodpovězení běžně (často negativně) ovlivní celou aplikaci včetně jejího objektového návrhu. Co je horší, v mnoha případech není vůbec jednoznačné, které řešení je to pravé, dokonce ani který druh úložiště. Navíc, pokud je něco „tím pravým“ nyní, nemusí tomu tak být natrvalo. Hledíme-li do budoucnosti, vznikají podobné problémy a otázky jako u platformní nezávislosti: Co se stane, když výrobce použité databáze zbanrotuje? Co když databázový systém přestane vyhovovat, ale jiný by by byl lepší..
Problém je ještě komplikovanější, pracujeme-li v heterogenním prostředí, které musí integrovat data z již existujících „legacy“ systémů. Jak provázat oba/všechny systémy, aniž by to negativně ovlivnilo objektový model? Jak si „nezavřít vrátka“ k jiným, modernějším možnostem ukládání, jakmile bude možné starý systém odstavit? Příslušné design patterns (které mimochodem demonstrují složitost takové operace) jsou v [mappatterns].
Většina vyvíjených aplikací je silně svázána s konkrétním úložištěm. A to je chyba.
Výběr úložiště nesmí ovlivnit objektový návrh
Aplikace nesmí být pevně svázána s žádným konkrétním úložištěm a dokonce s žádnou konkrétní třídou úložišť.
Změna úložiště musí být proveditelná pouhou rekonfigurací či doplněním části podpůrného nástroje, který zajistí perzistenci objektovému modelu aniž by se to dotklo kterékoliv jiné části aplikace (zejména objektového modelu nebo uživatelského rozhraní)
Aplikace by měla být schopna integrovat data z různých úložišť a dokonce z různých tříd úložišť
Zajištění perzistence by mělo být z hlediska programátorů a vývojářů co nejsnadnější
Pro odlehčení jeden fiktivní příběh:
Příklad 1. Vývoj nekončí odevzdáním
Vyvíjíme informační systém. Dejme tomu, že po posouzení všech pro a proti se rozhodneme data ukládat do relační databáze, dejme tomu do PostgreSQL. Po čase se zákazník rozhodne pronajmout si existující systém pro správu dokumentů, který ukládá data do XML databáze. Po nás požaduje, aby určité typy dokumentů v této databázi zpracovával rovněž námi dodaný informační systém. Díky správně navržené architektuře to nebude velký problém - integrujeme další úložiště (XML databázi) do podpůrného nástroje v perzistenční vrstvě. Budeme pravděpodobně muset přidat nějaké objekty reprezentující zpracovávané dokumenty do objektového modelu, o detaily ukládání se ovšem starat nemusíme - obslouží je příslušný podpůrný nástroj. Doposud funční části systému nebudou narušeny. Po čase se objeví nějaký nový, levný objektový databázový systém, který dokáže ukládat velice efektivně jak klasické objekty tak silně strukturované dokumenty a má velice dobře vyřešenou otázku bezpečnosti - prostě nádhera. Zákazník si vše propočítá a rozhodne se ukončit pronájem XML systému pro správu dokumentů a po nás bude chtít převést existující data do nového systému. Od nás to bude opět znamenat rekonfiguraci perzistenčního nástroje, ale objektového modelu se to vůbec nedotkne - příslušné objekty nebudou potřebovat ani rekompilaci...
Pohádka? Příliš komplikované? Každopádně, řešitelné - nástrojů, které se o něco podobného pokoušejí, existuje produktů mnoho a přibývají a vyvíjejí se v souladu s tím, jak se ukazuje, že univerzální přístup k úložištím je nezbytný.
První vývojovou fází většiny nástrojů je čisté objektově-relační mapování - nástroje zastřešují různé (ideálně všechny dostupné) RDBMS tak, aby se případná záměna nedotkla vlastní aplikace. Takových řešení je poměrně mnoho (možná desítky).
Druhá generace se snaží o skutečně univerzální přístup, jak byl popsán výše, tedy kromě RDBMS umožňují jednotně pracovat též s OODBMS, LDAP, souborovým systémem a většinou po doprogramování příslušného modulu obecně se vším. I těchto nástrojů existuje poměrně dost, ovšem jednen vybočuje svým vysoce kvalitním návrhem a snahou jít cestou standardů všude, kde je to možné.
Jakarta OJB (původně ObjectRelationalBridge, po kompletním přepracování a zuniverzálnění dále už jen OJB) je knihovna pro jazyk Java, která zpřístupňuje nejen relační databáze, ale teoreticky všechny běžné typy úložiště. Aplikace může přistupovat k úložišti přímo jednoduchým, ale proprietárním rozhraním nazvaným PersistenceBroker. OJB ale přidává další vrstvu abstrakce i směrem „dovnitř“, tedy k aplikaci a té tak umožňuje pracovat dle nejznámějších standardů - ODMG či JDO. Tato architektura je dobře vidět z obrázku, který jsem si půjčil z [ojb]
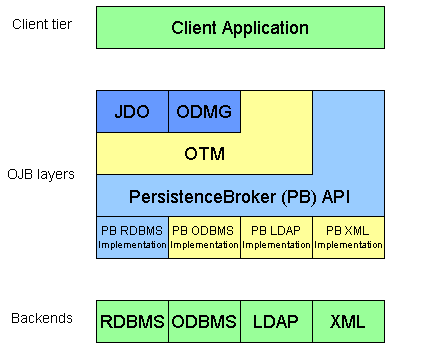
OJB dokáže pracovat jak ve vícevrstevné architektuře uvnitř EJB aplikačního serveru, tak u nevrstvené aplikace. Je, ostatně jako všechny jiné projekty Apache Jakarta, dobře dokumentována. Její novější verze se i docela snadno nastavují i používají. A je zadarmo, dokonce open-source. Sám jsem nepatrně jsem i přispěl k jejímu vývoji a její funkčnost odzkoušel na jednoduchých aplikacích. OJB je ale nasazena i v silně zatížených podmínkách na Internetu, u různých informačních systémů po celém světě a i leckde jinde. Vřele doporučuji.
- 6.1. Shrnutí možností
- 6.1.1. Tiskárna
- 6.1.2. Netiskové výstupy
- 6.2. Běžné chyby
- 6.2.1. Tiskárna
- 6.2.2. Netiskové výstupy
- 6.3. Požadavky ASM
- 6.3.1. Požadavek
- 6.4. Řešení v souladu s požadavky
- 6.4.1. XML
Nejběžnějším typem výstupu jak ho zde chápeme jsou tiskové sestavy. Ty je možné řešit proprietárním způsobem (jako vše) nebo využít některého ze standardních formátů pro popsání textové informace s přihlédnutím k její grafické podobě. Uvedu některé zástupce a v další části se pak krátce zamyslím nad výstupy, které nesměřují na papír.
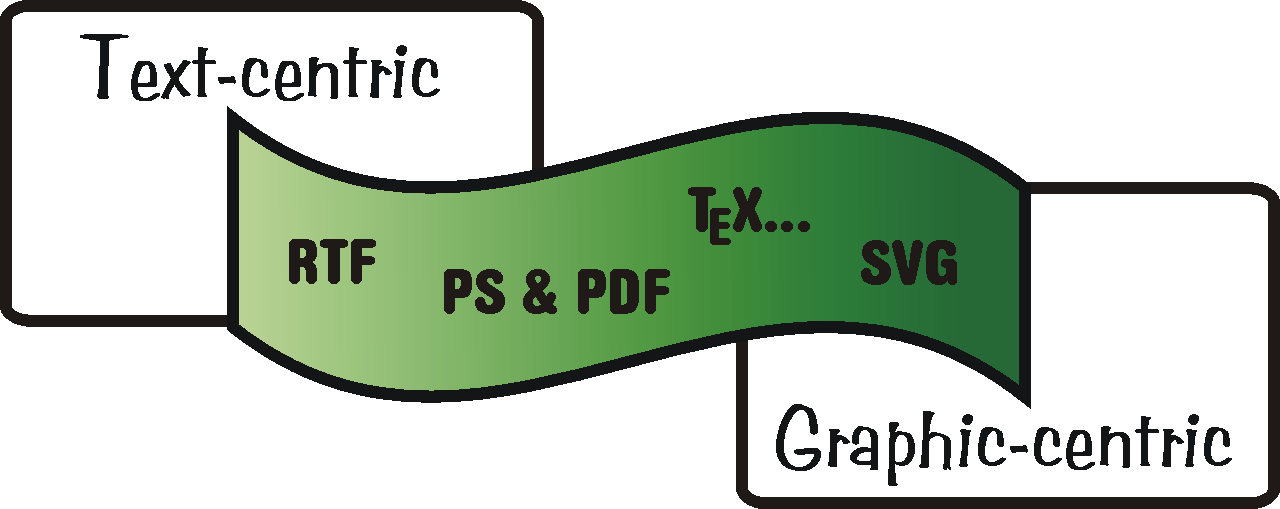
- RichText
RichTextFormat (RTF) je formát pro zachycení textu včetně formátování, struktury, dalších vlastností s použitím tisknutelných znakových sad. Mechanizmus „kontrolních příkazů“ nabízí jmenný prostor, který může být využit k definování speciálních znaků, ale různých vložených objektů, maker apod. [ffe] Jeho výjimečnost spočívá v tom, že je narozdíl od proprietárních formátů (DOC, WLS, SXC...) je standardizován a dobře popsán. Díky tomu může sloužit jako výměnný formát mezi různými textovými editory a kancelářskými balíky, jejichž nativní formáty jsou vzájemně nekompatibilní, ale i jako výstup is.
- PostScript
PostScript (PS) je jazyk určený pro popis stránek dokumentu nezávisle na výstupním zažízení respektive na jeho rozlišení. Tvůrcem tohoto jazyka je firma Adobe. Mnoho laserových tiskáren ho přímo zná, proto stačí dokument na tuto tiskárnu přímo poslat. Pokud PostScript tiskárna neumí interpretovat, je k tomu potřeba softwarový interpretr, např. GhostScript. Základní elementy v PostScriptu jsou Bézierova křivka, úsečka, text lze popsat přímo jako text avšak ve výsledku se písmena kreslí z oblouků. [postscript] Rozdíl oproti RTF spočívá ve snaze stránku popsat přesně a precizně , tedy tak jak je to třeba pro profesionálnější tiskový vzhled.
PortableDocumentFormat, tedy PDF je novější verzí PS, vnitřně komprimovaný, se zvýšenou přenositelností, podporou Unicode a mnoha jinými výhodami, princip i primání použití je ovšem stejné.
- TeX
Viz TeX je fenomén pocházející původně z UNIXů. Pod touto zkratkou se skrývá jak vlastní formát, tak množna programových nástrojů pro sazbu. V současnosti existují různé implementace pro všechny myslitelné platformy. Principielně zhruba odpovídá PDF..
- ScalableVectorGraphic
Jazyk pro popis dvourozměrné grafiky, založený na XML. SVG zná tři typy grafických objektů: vektorové grafické tvary (např. cesty skládající se z rovných linií a křivek), bitmapové obrázky a text. Grafické objekty mohou být seskupovány, dolaďovány použitím stylů, transformovány, komponovány do předrenderovaných objektů. Mezi interní funkce patří vnořené transformace, ořezové cesty, alfa masky, efekty a šablony. [svgspec]
Ano, SVG je především standardní grafický formát - schopnost uchovávat textové informace je až na druhém místě. Je to patrné i z toho, že MIME typ pro SVG je „image/svg+xml“.
Příklad 2. Prezentace (XHTML)
Informační systém může například za běhu generovat na základě objektového modelu XHTML obsah, dejme tomu stránku se základními informacemi o volných pracovních místech včetně oddělení, platových podmínkách ap.
Příklad 3. Logy, statistika.. (SQL)
Výstupem aplikace může být také například SQL INSERT příkaz, který doplní záznam v nějaké z hlediska zkoumaného is „cizí“databázi. Mám na mysli například nějaké logy, statistická data, informace pro prezentaci. Z databáze mohou být informace „vytahovány“a zobrazovány v podobě HTML s využitím některé ASP (v obecném slova smyslu) technologie. Takové další zpracování je ale již mimo oblast působnosti informačního systému, který popisujeme - pro ten vše končí odesláním SQL.
Základní nevýhoda formátů pro tiskový výstup spočívá v tom, že jsou nevhodné pro jiné použití - informace „chápou graficky“a neznají význam informací. Dejme tomu, že pro tiskové výstupy programu použijeme RTF. Ale co když si pořídíme PostScriptovou tiskárnu a budeme chtít využít její schopnosti pro zvýšení kvality výstupů? Tak je převedeme, možná řeknete a s jistými obtížemi se vám to podaří. Ano, tak jiná otázka: Co když podobné výstupy, jaké tisknete, budete posílat ke zpracování „cizímu“informačnímu systému, spravovaného například ministerstvem financí. A co když požadovaný formát bude vyžadovat VÍCE informací, než kolik jich je v RTF, takže automatizovaný převod bude znamenat spoustu práce při psaní nějakého převodního programu či schématu a nebo bude principielně neproveditelný. Ano, přijde to nejhorší - zásah do vlastní aplikace (do metod uvnitř tříd modelu). Shrneme-li výše uvedený příklad: Pouze graficky formátované informace jsou takřka nepoužitelné jinak, zejména strojově.
Příklad 6. Prezentace (XHTML) pokračování
Informační systém může například za běhu generovat na základě objektového modelu XHTML obsah, dejme tomu stránku se základními informacemi o volných pracovních místech včetně oddělení, platových podmínkách ap.
XHTML je pro účely prezentace jistě vhodný formát. Ale co když se rozhodneme využít služeb nějaké pracovní agentury, která je ochotna poskytnout nám práva k zápisu do určité části jejich relační databáze, ve které můžeme průběžně aktualizovat nabídky. Pokud chceme vše provádět automatizovaně i nadále, budeme muset upravit informační systém?
Příklad 7. Logy, statistika.. (SQL) pokračování
Výstupem aplikace může být také například SQL INSERT příkaz, který doplní záznam v nějaké z hlediska zkoumaného is „cizí“databázi. Mám na mysli například nějaké logy, statistická data, informace pro prezentaci. Z databáze mohou být informace „vytahovány“a zobrazovány v podobě HTML s využitím některé ASP (v obecném slova smyslu) technologie. Takové další zpracování je ale již mimo oblast působnosti informačního systému, který popisujeme - pro ten vše končí odesláním SQL.
Ale co když po čase zjistíme, že potřebujeme nikoliv SQL výstup, ale výstup například v nějakém proprietární textovém formátu? Bude to znamenat úpravu informačního systému? A co když budeme chtít ještě části výstupů tisknout? Tady není situace tak kritická, protože SQL, byť je pro výše uvedené použití nevhodný, obsahuje poměrně dost metainformací o charakteru posílaných dat - jsou skryty v použitých názvech tabulek a sloupců.
Příklad 8. Banka (proprietární) pokračování
Dejme tomu, že do banky chceme posílat příkazy k úhradám, žádosti o výpisy apod. Banka používá proprietární textový formát. Dobrá, přizpůsobíme se mu.
Po čase banka přejde na novější verzi informačního systému a původní formát se záhy stane zastaralým ve prospěch nového, založeného na XML standardu. Podpora zastaralého formátu po určité době skončí. Zase uparavit informační systém?! Nebo ponechat výstupy v zastaralém formátu, kterému za čas již nebude nikdo (ani člověk, ani počítačový systém) rozumět a vše vyřešit konverzním schématem?
Příklad 9. Elektronické podání (XML) pokračování
Dejme tomu, že stát umožní poplatníkům podávat daňová přiznání k DPH v elektronické podobě, ve formátu založeném na XML.
V rámci přibližování se EU se Zákon o DPH se změní a změní se i podporované schéma přiznání, byť údaje obsažené v přiznání zůstanou v zásadě stejné. Jak to ovlivní informační systém?
Nezbytným předpokladem úspěšného řešení je zachování co největšího množství informací a metainformací v primárním výstupu. Bude-li primární výstup dostatečně informačně bohatý, finálního výstupu docílíme poměrně snadno sestavením transformačního schématu, které ovšem nijak neovlivní vlastní informční systém. Transformace může proběhnout „vně“. Přiložený obrázek [kosek] demonstruje snadnost transformace z informačně bohatšího zdroje do informačně chudšího formátu.
Jaký formát dokáže zachytit v zásadě libovolné informace, aniž by je nějak „okleštil“? Už nebudu dále chodit kolem horké kaše a řeknu to na rovinu: pro primární výstup použijte XML s vhodným schématem, a ten transformujte dle XSLT šablony do výsledného výstupu. Nyní stručně připomenu co je to XML, „schéma“ a XSLT pro případ, že byste se s těmito pojmy ještě nesetkali a dále zmíním jednen nástroj, který by mohl usnadnit a zpřehlednit generování různých výstupů z různých XML zdrojů, pokud by se situace ve vašich výstupech stala nepřehlednou.
XML= eXtensible Markup Language. XML umožňuje definovat vlastní sady „tagů“, konkrétní podle typu zachychené informace. Příkladem jednoduchého XML dokumentu (bez záhlaví) je následující popis výrobku:
<pecivo> <nazev>rohlik</nazev> <cena>2</cena> <mena>Kč</mena> </pecivo> |
Možná namítnete, co je na tom tak zvláštního, v čem se to liší například od takovéhoto dokumentu (který je mimochodem znatelně kompaktnější):
pecivo nazev:"rohlik" cena:"2" mena:"Kč" |
Máte pravdu, že informačně je druhý (neXML) dokument stejně bohatý. Skutečné výhody XML se objeví, až když se zkombinuje s dalšími existujícími standardy a nástroji. XML má totiž v tomto smyslu vybudovanou kvalitní infrastrukturu, jinými slovy první dokument existujícími nástroji můžete snadno (bezpracně) reprezentovat stromovou datovou strukturou uvnitř vámi vyráběného programu, snadno ho převedete do zobrazitelné podoby (u které snadno změníte způsob zobrazení), snadno ho upravíte v XML editoru... Navíc existují schémata pro různé oblasti využití, pro která jsou opět hotové nástroje, transformační schémata... Omlouvám se - schémata jsou teprve před námi.
- DTD
Definice typu dokumentu (DTD ) říká, které elementy a atributy můžeme v dokumentu použít. Navíc je zde definováno, v jakých vzájemných vztazích mohou být jednotlivé elementy použity. DTD je tedy užitečný nástroj, který nám umožní hlídat, zda mají naše dokumenty správnou strukturu. Ve světě se používá mnoho DTD, které vyhovují různým požadavkům. Mezi jedno z nejznámějších patří například DocBook, které definuje elementy a atributy vhodné pro značkování technické dokumentace. Tím, že naše dokumenty založíme na určitému DTD, získáme hned dvě výhody. Jednak můžeme pomocí parseru kontrolovat, zda má náš dokument správnou strukturu. Druhá výhoda je patrná při použití standardních DTD jako HTML nebo DocBook -- k dispozici budeme mít mnoho užitečných a jednoúčelových nástrojů navrhnutých pro konkrétní DTD. [kosek]
Mimochodem tato práce byla psána právě s využitím DocBooku. Díky tomu může být snadno převedena do XHTML (a to třeba jako jeden dokument nebo struktura rozdělená dle kapitol do jednotlivých souborů...), PDF, RTF s možností určit jak má v tom kterém formátu vypadat. To není ale vše - může být snadno zpracovatelná nějakým systémem pro správu dokumentů (který pozná, co je nadpis, odstavec, citát, anotační údaj, klíčové slovo ap.)... Jelikož DocBook je poměrně rozšířeným standardem, není problém příslušné transformační šablony najít a... použít. Proto, chcete-li si ušetřit práci pokuste se najít standardní schéma, které by odpovídalo typu informací primárního výstupu. Pokud ovšem schéma nenajdete, nebojte se vytvořit svoje, alespoň mu pak budete dobře rozumět.
- XML Schema
DTD je bohužel až příliš jednoduchý a zastaralý formát. Má řadu nevýhod, které se pokouší řešit novější standardy, které dělají „to samé, ale lépe“ a principielně se tedy od DTD neliší. Nejstandardnějším standardem (protože pokusů a snah bylo a je více) je XML Schema od W3C konzorcia. Nebudu popisovat detaily, pouze shrnu, například v kterých směrech je XML Schema lepší: [schemavsdtd]
Strong typing - mnohem preciznější možnosti definice struktury dokumentu
Standardní reprezentace chybějících hodnot (null)
Jemnější jednoznačné identifikátory - V DTD pro jednoznačné identifikování elementu můžeme použít ID atribut. Ten musí být unikátní v rámci celého dokumentu. XML Schema dovoluje „unikátnost“omezit na nějakou jeho část.
Schémata jsou XML - DTD vyžaduje jiný způsob zpracování než XML. Protože XML Schema je XML, můžeme na něj použít stejné nástroje (parsery, editory...)
Co použít - DTD nebo XML Schema? Odpověď není úplně jednoznačná, protože závisí na konkrétní situaci. Obecně bych ale doporučil použít XML Schema, zejména pokud některá z jeho „vlastností navíc“ je pro vás důležitá nebo pokud si můžete dovolit myslet na budoucnost. Pochopitelnou nevýhodou XML Schema je oproti DTD značná složitost, což se projevuje v drobné váhavosti v přecházení na tento standard. XML Schema je mladé, tudíž trpí typickým neduhem mladých standardů: mnoha jinak užitečným nástrojům podpora XML Schema (zatím) chybí. Je tady ještě jeden fakt: Existují rozsáhlé knihovny propracovaných DTD. Někdo by z toho mohl usuzovat, že DTD přetrvá věky. Osobně si myslím, že jakmile podpora XML Scheme bude dostatečná, nebude žádný omluvitelný důvod u DTD setrvávat. Existující DTD bude poté možné automatizovaně přetransformovat do XML Scheme, nástroje již existují.
XSLT je určen pro transformaci XML dokumentů do jiných (zejména XML) podob. Jeho základem jsou předlohy (templates) pro jednotlivé elementy. Každý element, který má být transformován má svou šablonu, která říká jak má být přeložen. Např. [transformace]
<xsl:template match="duraz"> <i> <xsl:apply-templates /> </i> </xsl:template> |
lze v XSLT využít pro převod všech elementů se jménem „duraz“ (tedy něčeho na co má být položen důraz) na „i“- tedy na kurzívu dle XHTML. [transformace]
Pro usnadnění provádění hromadných transformací existuje několik zajímavých systémů. Za zmínku stojí například Apache Cocoon cocoon, určený především na generování stránek pro WWW prezentace z všemožných datových zdrojů - především z XML. Je ale navržený natolik univerzálně, že by mohl výhodně posloužit i jako vrstva obchodní aplikace zodpovědná za vytváření konečných neinteraktivních výstupů, ovšem toto použití jsem zatím neověřil v praxi.
A co bude finálním výstupem? To již nechám na Vás, protože každý formát má svá pro a proti a zejména svá vhodná a nevhodná použití. Pouze se, prosím, pokuste jít cestou uznávaných standardů či alespoň de-fakto standardů. Volba proprietárního řešení může být krátkodobě pohodlnější, ale vzpomeňte - vždy vás na konec poškodí.
- 7.1. Shrnutí možností
- 7.1.1. Scénář desktop
- 7.1.2. Scénář z intranetu
- 7.1.3. Scénář z Internetu
- 7.1.4. Scénář mobilní
- 7.1.5. Scénář hendikepovaní
- 7.2. Běžné chyby
- 7.3. Požadavky ASM
- 7.3.1. Požadavek
- 7.4. Řešení v souladu s požadavky

Zdaleka nejběžnějším typem uživatelského rozhraní je grafické uživatelské rozhraní (gui). V současné době jeho vytváření probíhá jako manuální skládání jednotlivých obrazovek z primitivních komponent, jakými jsou například vstupní pole, zaškrtávací políčka, výběrové seznamy ap. a následné propojení s modelem pomocí tzv. událostí. Komponenty uživatelského rozhraní bývají označovány též jako „widgety“.
Každý programovací jazyk má svou sadu komponent, podobně i například jazyk HTML má odpovídající sady formulářových tagů (Forms, XForms, XUL..). V následujících oddílech shrnu možné scénáře ui na příkladech konkrétních technologií. Pokud jsou implementace konkrétních scénářů závislé na konkrétním programovacím jazyce, použiji příklad z Javy.
Z grafických uživatelských rozhraní doposud drtivě převažuje právě tento typ. Vzhled je včleněn do „oken“, ta se skládají z běžných i méně běžných widgetů, převzatých z programovacího jazyka či vývojového prostředí, ve kterém je aplikace tvořena a z jejich derivátů. Výřez okna editoru XML Mind (ve kterem píši tento dokument), aplikace s docela typickým „desktop“ vzhledem, vám možná trochu přiblíží, co tím myslím:
V Javě byl takovou sadou komponent AWT, tento balík je ovšem zastaralý, nahradil ho nověji JFC, jehož novější verze jsou známy pod kódovým jménem Swing. Tato knihovna je svým návrhem, funkcemi a použitelností jednou z nejlepších vůbec, proto si přiblížíme některé její části a schopnosti: [j2sdk]
Komponenty - zahrnují vše od tlačítek až k rozdělovačům obrazovky a tabulkám.
Výměnný vzhled a chování - Každý program, který využívá Swing komponenty, si může vybrat, jak mají vypadat a jak se mají chovat. Například stejný program může jednou vypadat jako klasická MS Windows aplikace, podruhé jako Gnome a nakonec kovově („Metal“ l&f je výchozí). Kdokoliv může vytvořit balíček vzhledu a chování, pokud si z existujících nevybere - v úvahu připadá třeba i využití zvuku místo obrazu.
Usnadnění - API pro zapojení technologií jako např. čtečky obrazu, Braillovy panely
Java2D API - Možnost zahrnout kvalitní 2D grafiku, text a obrázky
Drag and Drop - Schopnost přetahovat informace mezi Swing rozhraním a nativním prostředím
Systémy spadající do stejného scénáře jako Swing se obvykle vyznačují například těmito přednostmi:
jednoduchost použití
bohaté možnosti
stabilita, vyspělost, spolehlivost
- XWindow
Systém XWindow, dodávající grafické uživatelské rozhraní UNIXům předběhl dobu - už od svých počátků nabízel i přes „desktop“charakter aplikací možnost pracovat distribuovaně. Tento systém funguje jednoduše řečeno tak, že server zobrazuje programy na dálku, tedy u klienta. Nevýhodou jsou značné nároky na server a přenosový kanál a také nezbytné softwarové vybavení klienta, proto je použitelný prakticky výhradně na intranetech.
- Java applety
Technologie, která umožňnuje včlenit aplikaci se Swing uživatelským rozhraním (pouze některé funkce jsou omezené či zakázané) do HTML stránky a výsledek, pokud se zveřejní na internetu, je možné spustit prakticky odkudkoliv. Zdálo by se, že applety jsou dokonalým řešením, jeho nevýhody ale nejsou zanedbatelné: Například vyžaduje stažení poměrně velikého programu před jeho spuštěním, prohlížeč musí být vybaven správnou verzí JVM a správně nakonfigurován, výsledný applet přeci jenom všechno neumí. Dáme-li vše výše uvedené dohromady, nepřekvapí nás, že tato technologie si udělala špatné jméno svou nespolehlivostí a nestabilitou a proto se používá téměř výhradně v rámci intranetů, kde tyto nevýhody nejsou až tak moc citelné.
Různé aplikace na Internetu jsou (a budou) čím dál významější, prostředky pro jejich vytváření proto přibývají jako houby po dešti a jsou velice různorodé. Stručné a přehledné srovnání přístupů (nikoliv konrétních nástrojů) jsem nikde nenašel, proto jsem se tomuto námětu věnoval o trošičku více, ale i tak je to pouhý rozcestník..
Populárním termínem v této oblasti je MVC , tedy model-view-controller architektura. I přes svou značnou popularitu toho MVC příliš mnoho neříká a prakticky cokoliv o sobě může prohlašovat, že je implentuje MVC přístup. Klíčová myšlenka MVC by se mohla shrnout slovem „oddělenost“. Model, vzhled i kontroler musí být maximálně oddělené jeden od druhého a komunikovat přes co nejužší, jasně vymezené rozhraní. Tato zásada je všeobecně přijímána jako důležitý předpoklad dosažení flexibility a snadné spravovatelnosti. V dalších částech se zamyslíme nad konkrétními typy MVC technologií pro prostředí webu. Termín „model“ se poměrně dobře kryje s tím, jak jej zde chápeme a mohli jste si o něm přečíst něco v 2 – „Model“, proto jej dále nebudu zkoumat. Z logického celku „view“ prozkoumáme postupy vytváření dynamického obsahu a poté se dokneme standardů pro vlastní formulářové prvky. O části „controller“ se zmíním na závěr, hodně stručně.
Principem aplikací na webu je nějakým způsobem implementovaná logika vytváření stránek a zpracovávání uživatelských vstupů, zkrátka to, co dodává běžným (a tedy statickým) HTML stránkám dynamiku. Je možné odlišit dva principielně odlišné přístupy, někdy označované jako „push“a „pull“. Historicky starší je pull přístup a funguje tak, že do jinak statické stránky „dotáhne“ dynamický obsah. Důležitým momentem je zde to, že tento proces je iniciován a řízen „z pohledu“ statické stránky.
Klasickým příkladem pull technologie jsou skripty včleněné do HTML stránky (ASP, PHP, JSP, ..). Výzkumy i zkušenosti čím dál tím jasněji ukazují, že tento přístup nevede k vytvoření snadno spravovatelné, flexibilní webové aplikace. Základní příčinou je jednoduchý fakt, že není technicky zaručeno, aby obsah, vzhled a logika byly maximálně odděleny a naopak jsou nabízeny prostředky k implementaci koncepčně špatných řešení, která jsou u pull technologií technicky neproveditelná. Silná stránka skriptovacích jazyků („moc“ a značné schopnosti) je v důsledku slabinou. O trochu méně výrazný, ale pořád ještě dostatečně nepříjemný je tento problém u „template engines“ (Velocity, WebMacro, FreeMarker, WebMacro, Tea,...), které jsou principielně ekvivalentní skriptování. Jejich výhodou je, že to nejsou plnohodnotné programovací jazyky, a tak nabízejí o něco méně možností k prohřeškům. Více v tomto směru např xmlcvsjsp.
Technologie umožňující obojí přístup existují od samého začátku dynamických stránek. Mám na mysli CGI skripty, tedy samostatně spustitelné programy, jejichž jediným úkolem je generovat výsledný kód stránky. Principielně shodné s CGI jsou servlety (vlastně CGI napsané v Javě). Jakým způsobem si výsledek sestaví, je jejich soukromou věcí - mohou kombinovat kód programu se statickým obsahem (pull) anebo načíst šablonu stránky a vhodně ji doplnit (push).
Prosím, nenechte se zmást reklamou technologií, která bude jistě tvrdit, že umožňuje oddělit vzhled, logiku a obsah. Skutečně, v zásadě všechny to umožňují, ale žádná z výše uvedených to nemůže zaručit.
Push technologie jsou naopak k takové záruce o dost blíže. Musíte se opravdu snažit, abyste princip oddělenosti porušili, a i to se vám podaří jen částečně. Zásadní, ale velice praktické omezení spočívá v tom, že šablona, zdrojová stránka (nejspíše XHTML ) prostě je statická a není žádný způsob, jak to změnit. Program načte ve vhodné podobě tuto čistě statickou stránku a „vtlačí“ do ní na požadovaná místa dynamický obsah. Statická stránka je zde jakýmsi „substrátem“ na kterém program dodávající dynamický obsah pracuje.
Příkladem produktu, který implementuje push přístup je open-source projekt Enhydra XMLC. Návrhář stránek použije svůj oblíbený editor a pouze místa, kde má stránka obsahovat dynamický obsah, označí id atributem a o logiku „dotlačení“ dat se nestará. XMLC kompilátor z takové stránky sestaví specifickou DOM (stromovou) reprezentaci, a usnadní programátorovi přístup k označeným místům, určeným pro dynamický obsah. Programátor doplní postup získání dynamického obsahu a snadno ho včlení do stránky se zachováním jednotného vzhledu. Tento postup schematicky znázorňuje obrázek, který jsem si půjčil z [xmlcvsjsp]:
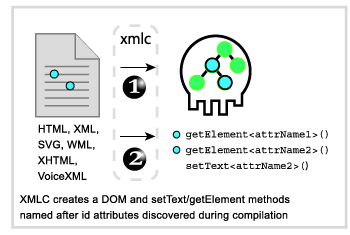
Obdobou desktopových „widgetů“ jsou pro webové vývojáře tzv. formulářové tagy. Klasickým řešením jsou HTML forms, tedy HTML formuláře, součást specifikace HTML jazyka. Jsou široce rozšířené a široce podporované. Snadno se kombinují s jinými prvky HTML jazyka, takže výsledná aplikace vypadá v mnoha případech „moderněji“ a „lehčeji“ než její monoliticky působící desktopový dvojník. Trpí ovšem některými chybami: příliš zjednodušující, míchá obsah a vzhled nežádoucím (správu znesnadňujícím) způsobem, narozdíl od desktop řešení mají značně omezenou množinou použitelných grafických prvků... Kandidátem na místo formulářových značek je standard XForms.
Podpora všech typů prohlížečů včetně handheldů, televizí, počítačů, tiskáren a skenerů
Bohatší uživatelské rozhraní
Oddělení dat, logiky a vzhledu
Snadnější podpora více jazyků
Strukturovaná data
Pokročilá formulářová logika
Více formulářů na stránce a více stránek tvořících jeden formulář
Pozastavení a obnova
Integrace s dalšími XML značkovacími jazkyky
Zdá se, že XForms nemají chybu. Ano, je to dobrý standard, ale stejně jako HTML Forms má jedno podstatné funkční omezení, které způsobuje, že trochu pokulhává za desktop řešeními: vše co zná jsou formuláře. Formuláře je možné pouze vyplnit a odeslat, což je ve srovnání s komfortem destop řešení docela málo. Například pro interaktivní práci s daty z databáze (ve smyslu přidávání, úprava a odebírání záznamů...) nejsou příliš pohodlné. Další (a prozatím kritickou) nevýhodou je doposud nedostatečná podpora ze strany prohlížečů (zejm. IE a Navigator) i vývojových nástrojů.
Jiný projekt, řešící nedostatečnost standardních HTML formulářů nese název XUL. Je zaštítěný jednou společností Mozillou, tedy nikoliv standardizační autoritou a podle mého drobného výzkumu je také o něco hůře navržený než XForms, nicméně úplně jej ignorovat nemůžeme.
Existuje mnoho systémů, jejichž hlavním posláním je usnadnit navigaci uživatele po dynamicky generovaných stránkách, sledovat sezení apod. Většina těchto systémů řeší navíc další běžné úkoly související s vytvářením aplikací pro tak heterogenní prostředí, jakým je Internet - např. lokalizace či bezpečnost (security). Spolupracují se systémy pro generování dynamických stránek, z nichž některé jsme zmínili výše. Patří sem Tapestry, Barracuda, Struts, Turbine a další. Pěkné srovnání je například na stránkách wafer, proto se tímto námětem nebudu blíže zabývat.
I s mobilními telefony a různými PDA zařízeními je nutno počítat - „mobilní aplikace“ budou pravděpodobně jedním z nosných směrů blízké budoucnosti. Existuje obdoba jazyka HTML (WML), dále speciálně upravený virtuální stroj javy včetně nejnutnějších knihoven (J2ME) a různé další pomůcky, nástroje, standardy a technologie. Nebudu zabíhat do podrobností, pouze připomenu, že uživatelské rozhraní na podobných zařízení má svá specifika, především si musí poradit s velikostí displeje zařízení, nesmí také vyžadovat nadbytečné datové přenosy nebo „myšově orientovanou“ výraznou interaktivitu... Určité ambice v tomto směru má standard XForms.
Kromě grafických výstupů má význam uvažovat též rozhraní pro slabozraké a nevidomé, např. systémy s Braillovým písmem a zejména zvukové. Rozhraní pro hendikepované vyžadují kompletně odlišný přístup. Nové možnosti se otvírají v souvislosti s pokrokem systémů umělé inteligence z oblasti rozpoznávání mluvené řeči. Vytvoření podobného rozhraní pro složitější aplikace je zatím velice pracné a nevím o žádné běžně použitelné „knihovně zvukových widgetů“. Je pravda, že takováto rozhraní nemají tu nejvyšší prioritu, ale striktně odmítnout možnost vytvářet aplikace s podporou pro hendikepované lidi by bylo diskriminující a nerozumné i z obchodního hlediska, zejména v přípdadě, že by tím složitost vývoje a správy aplikace nebyla výrazně dotčena.
Swing teoreticky umožňuje vytvořit zvukový l&f. Potíž je v tom, že widgety jsou navrženy zejména pro grafická rozhraní, a tak obsahují mnoho informací o tom, jak mají vypadat, kde mají být ve formuláři apod., ale chybí jim specifické informace pro snadnou implementaci principielně odlišných scénářů. Řešením by byla nějaká mezivrstva, která by obsahovala maximum informací o modelu a ty byla schopna převést či předat jak do specificky grafické reprezentace (např. Swingu), tak do jakékoliv jiné...
Jaké sady widgetů či tagů využít? Tato otázka je poměrně komplikovaná, zejména když je nutné počítat s různými typy klientů. Klasický vzhled má nesporné výhody, ale uživatelé chtěji svá data odkudkoliv, třeba i z internetové kavárny nebo mobilního telefonu. Situace je ještě více komplikovaná tím, že současný stav na poli technologií uživatelského rozhraní není jistě definitivní. Co když bude potřeba v budoucnosti podporovat nějaký další typ klienta? Co když klienti pro námi zvolený typ uživatelského rozhraní přejdou na jiný standard?
Z hlediska ASM je zásadní chybou omezit se na jediný typ ui.
Uživatelské rozhraní nesmí snížit kvalitu objektového návrhu
ASM aplikace nesmí být závislá na použitém uživatelském rozhraní, naopak musí být snadno přizpůsobitelná jakémukoliv uživatelskému rozhraní pouhou rekonfigurací pomůcky, která vytvoří prezenční vrstvu aniž by se to jakkoliv dotklo jakékoliv jiné části aplikace (objektového modelu, jiných podporovaných uživatelských rozhraní či dokonce perzistenční vrstvy).
Uživatelské rozhraní musí být odvozeno od objektového modelu, dynamicky se mu přizpůsobovat pokud možno co nejvíce automatizovaně, ale zároveň umožnit „doladění“podle potřeb uživatelů.
Zdá se vám požadavek nerealistický? Nedivím se vašim pochybám. Výběrem z existujících nástrojů a zejména disciplínou při návrhu i vývoji je možné dosáhnout požadovaného oddělení modelu a vzhledu. S ostatními body je ale potíž - vhodný nástroj prostě neexistuje. Nebo, abych byl přesný, až donedávna neexistoval, a tak jsem zahájil jeho vývoj.
Nástroj dostal název Xermes. Serverová část generuje formuláře uživatelského rozhraní ve formátu nezávislém na konkrétním scénáři ui. Tyto formuláře jsou interpretovány klientskou částí Xermesu a přetvořeny do konkrétní podoby komponent uživatelského rozhraní. Veškerá komunikace mezi klientem a serverem probíhá v XML.
Prozatím je vytvořen klientský modul využívající primitivní komponenty knihovny Swing, v nejbližší době (až bude dokončena analýza vhodného řešení) bude následovat klient pro prostředí Internetu, využívající nejspíše HTML formuláře a XMLC pro snadné včlenění do konkrétních stránek. Podstatné ovšem je, že architektura systému umožňuje doplnit klientskou část pro prakticky každý jmenovaný scénář. Více informací o projektu najdete v příloze A – „Xermes - přehled“ nebo na jeho stránkách - xermes. Ty jsou ovšem trochu zastaralé, proto je neberte příliš vážně.
- 8.1. Shrnutí
- 8.2. ASM aplikace jako celek
V předchozích kapitolách jsme zkoumali jednotlivé části obchodní aplikace, tedy model, uživatelské rozhraní, neinteraktivní rozhraní a úložiště. Zajímalo nás také prostředí, ve kterém aplikace poběží a dále její infrastruktura (tedy architektura z hlediska distribuovatelnosti). Respektováním základního principu ASM, tedy principu obalu (viz 1.4.3 – „Požadavky ASM“) jsme se snažili dospět k takovým řešením, která povedou k flexibilitě, nezávislosti a schopnosti snadné změny, protože právě tyto vlastnosti jsou klíčové při vytváření aplikace, která má být snadno spravovatelná, robustní, schopná budoucího vývoje v souladu s rostoucími požadavky, škálovatelná. V dokumentu jsem také předal některé své zkušenosti s hledáním vhodných řešení, která by naplnila tyto požadavky.
Na obrázku je ASM aplikace z ptačí perspektivy s větším důrazem na konkrétní strukturu, než jak tomu bylo na obrázku v úvodu. Vše od modelu doleva je perzistenční modul, napravo je neinteraktivní rozhraní, dole je uživatelské rozhraní. Zeleně jsou zobrazeny části Xermesu (viz 7.4 – „Řešení v souladu s požadavky“), které jsou již funkční, žluté jsou příklady klientských částí, které se plánují. Světle modré jsou další podpůrné systémy aplikace, které již existují a stačí je využít.
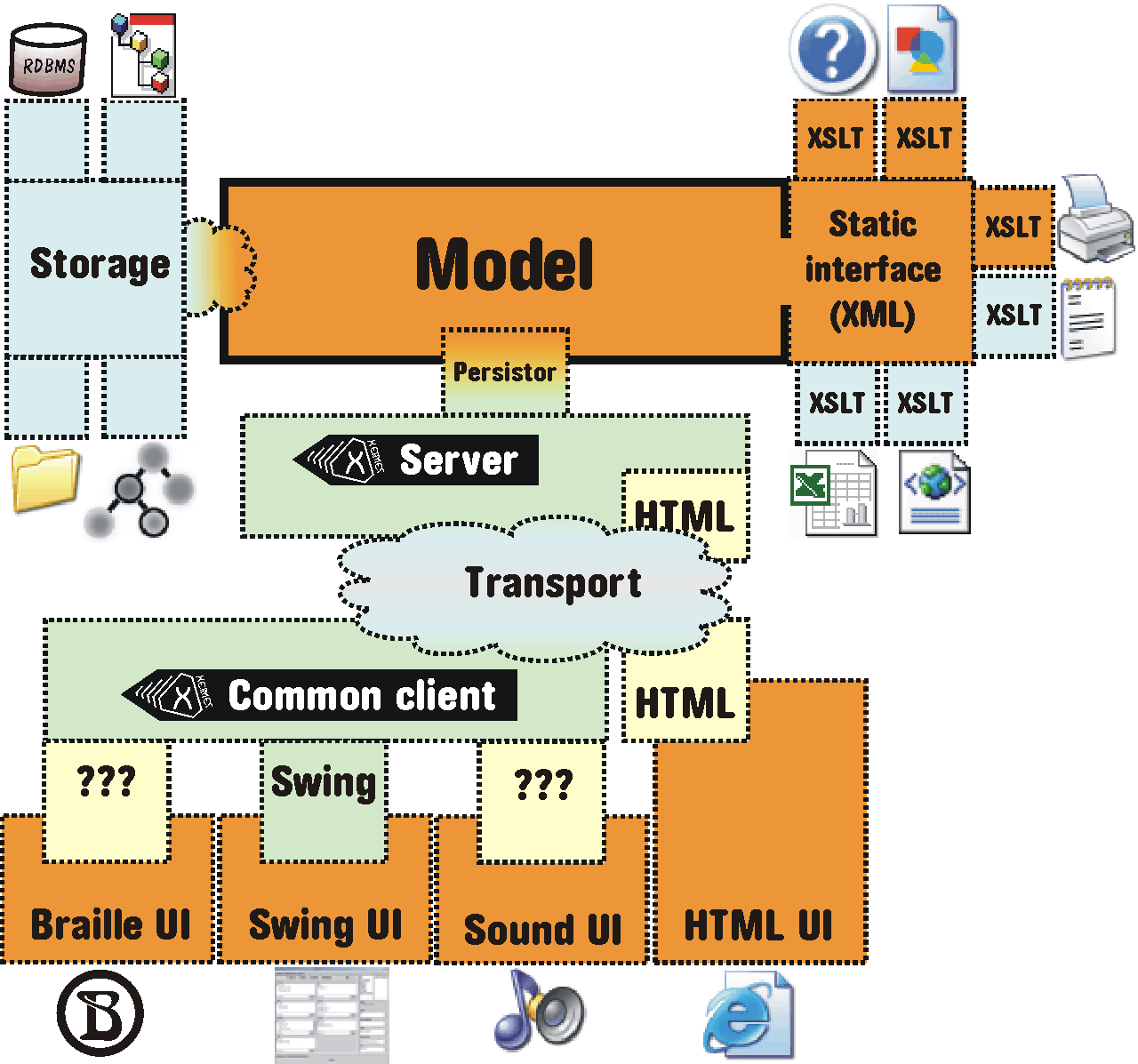
Budete-li takovou aplikaci vytvářet, musíte naprogramovat zejména model. Ve všem ostatním vám pomohou již existující nástroje. Budete muset ještě dovytvořit to, co je na obrázku zvýrazněno oranžově, tedy:
nezbytná spojení s úložištěm
nezbytné vstupy a výstupy neuživatelského rozhraní v jazyce založeném na XML
ty části uživatelského rozhraní, které není možné přímo odvodit z modelu
Základní myšlenkou ASM je „princip obalu “, který můžeme shrnout asi takto: Klíčový je model - vše ostatní je obal.
 |
Primární cíle a výsledky uplatnění tohoto principu jsou:
nezávislost
flexibilita
změna
Uvedli jsme si rovněž příklady druhotných přínosů:
snadná údržba
robustnost
trvalá hodnota
vpřed postupující vývoj
znovupoužitelnost
U jednotlivých částí ASM aplikace jsme definovali požadavky ASM, které aplikace musí, případně nesmí obsahovat a vlastností, které by měla, případně neměla obsahovat, aby byla vytvořena v souladu s principem obalu a výše uvedených cílů mohla dosáhnout. Nyní si požadavky shrneme:
- Model
Je potřeba zvolit model, který má dostatečné vyjadřovací schopnosti, a tak umožní vytvoření flexibilní aplikace.
- Platforma
ASM aplikace by měla fungovat na kterékoliv platformě.
Změnou hardwaru či operačního systému kteréhokoliv z počítačů by funkčnost aplikace měla zůstat nedotčena.
- Infrastruktura
ASM aplikace musí být snadno škálovatelná a to nejlépe z jednoduché desktop aplikace, přes různé klient server modifikace, až po třívrstevný model s aplikačním serverem uprostřed.
Druh nasazení by neměl zvyšovat komplexitu objektového modelu a vývojářům by mělo být tak říkajíc jedno, v jak distribuovaném prostředí aplikace poběží.
- Úložiště
Výběr úložiště nesmí ovlivnit objektový návrh
Aplikace nesmí být pevně svázána s žádným konkrétním úložištěm a dokonce s žádnou konkrétní třídou úložišť.
Změna úložiště musí být proveditelná pouhou rekonfigurací či doplněním části podpůrného nástroje, který zajistí perzistenci objektovému modelu aniž by se to dotklo kterékoliv jiné části aplikace (zejména objektového modelu nebo uživatelského rozhraní)
Aplikace by měla být schopna integrovat data z různých úložišť a dokonce z různých tříd úložišť
Zajištění perzistence by mělo být z hlediska programátorů a vývojářů co nejsnadnější
- Neinteraktivní rozhraní
U ASM aplikace musí být změna konkrétního výstupního formátu neinteraktivních sestav možná a maximálně snadná a nesmí vyžadovat zásahy do modelu.
- Uživatelské rozhraní
Uživatelské rozhraní nesmí snížit kvalitu objektového návrhu
ASM aplikace nesmí být závislá na použitém uživatelském rozhraní, naopak musí být snadno přizpůsobitelná jakémukoliv uživatelskému rozhraní pouhou rekonfigurací pomůcky, která vytvoří prezenční vrstvu aniž by se to jakkoliv dotklo jakékoliv jiné části aplikace (objektového modelu, jiných podporovaných uživatelských rozhraní či dokonce perzistenční vrstvy).
Uživatelské rozhraní musí být odvozeno od objektového modelu, dynamicky se mu přizpůsobovat pokud možno co nejvíce automatizovaně, ale zároveň umožnit „doladění“ podle potřeb uživatelů.
Příloha A. Xermes - přehled
- A.1. Abstraktní reflexe
- A.2. Server
- A.3. ACIL
- A.4. Klient
- A.4.1. Swing klient
- A.4.2. Jiní klienti
- A.5. Shrnutí
- A.5.1. Přínosy
- A.5.2. Závislosti
- A.5.3. Licence
- A.5.4. Stav a vývoj
Xermes je klient/server framework pro zpřístupnění objektů aplikace uživatelskému rozhraní. Obsahuje zejména:
- xermes.areflect
Balíček abstraktní reflexe, nadstavba reflexe a flexibilnější obdoba introspekce známé ze specifikace JavaBeans - viz beans. Prozkoumá třídu, dle pravidel (která je možné měnit) nalezne vlastnosti a metody a vytvoří abstraktní třídu (AClass). Abstraktní třída nabízí prostředky pro univerzální přístup k vlastnostem a metodám třídy, charakterem je tedy „dekorátor“ - co to znamená viz tip.
- xermes.server
Balíček s třídami které „napojí“ objekty aplikace do komunikačního kanálu s uživatelským rozhraním.
- xermes.client
Balíček s třídami pro usnadnění vytváření klientů pro komunikaci se serverem. Součástí je demonstrační implementace Swing Xermes klienta, přibydou další.
Balíček abstraktní reflexe je jádrem systému, poskytuje serveru prostředky pro práci s objekty modelu. Na dalších řádcích uvedu příklad jeho využití, kód bude samozřejmě v Javě. Pokud nejste programátor, asi vám bude tato pasáž připadat trochu méně srozumitelná a možná ji tak raději přeskočíte...
Mějme třídu HumanBeing například takovouto:
public class HumanBeing
{
public int age = 0;
public String getName() {/* some code */}
public void setName(String name) {/* some code */}
public Vector obtainFriends() {/* some code */}
public void remFriend(String friend) {/* some code */}
public void addFriend(String friend) {/* some code */}
} |
Dejme tomu, že potřebujeme vytvořit instanci této třídy, objekt Tonda, zaevidovat jeho kamarády a pak všechny zachycené informace vypsat. Nejpřirozenější řešení tohoto úkolu bude vypadat asi takto:
Příklad A.1. Přímá práce s objektem
//vytvoreni Tondy
HumanBeing tonda = new HumanBeing();
//nastaveni jmena
tonda.setName("Tonda");
//dodani kamaradu
tonda.addFriend("Jirka");
tonda.addFriend("Helena");
//precteni jmena
String name = tonda.getName();
//precteni kamaradu
Vector friends = tonda.obtainFriends();
//vypis kamaradu
System.out.println(name+" ma kamarady:");
Iterator iter = friends.iterator();
while (iter.hasNext())
System.out.println(iter.next()); |
Proč je tedy potřeba vytvářet nějakou další vrstvu pro přístup k vlastnostem a metodám, když se s nimi pracuje tak snadno? Potíž je v tom, že výše uvedený kód předpokládá, že třída, s jejíž instancí pracuje, je dopředu známá, tedy programátor musí znát třídu HumanBeing včetně jejího veřejného rozhraní, než tento kód napíše a zejména kompilátor ji musí znát, než kód zkompiluje. Vzniká otázka, jak je možné docílit toho samého, ale bez nutnosti znát třídu v době vytváření kódu.
Nejstarším řešením tohoto problému je v Javě tzv. reflexe j2sdk- tedy lapidárně řečeno schopnost třídy „představit se“ - za běhu nabídnout především seznam svých metod a datových polí k použití. Podívejme se, jak je možné využít reflexi pro dosažení stejného výsledku jako v příkladě výše:
Příklad A.2. Reflexe
//vytvoreni Tondy
String className = "xermes.areflect.example.HumanBeing";
Class humanClass = HumanBeing.class.forName(className);
Object tonda = humanClass.newInstance();
//nastaveni jmena
Method setName = humanClass.getMethod("setName",new Class[] {String.class});
setName.invoke(tonda, new Object[] {"Tonda"});
//dodani kamaradu
Method addFriend = humanClass.getMethod("addFriend",new Class[] {String.class});
addFriend.invoke(tonda, new Object[] {"Jirka"});
addFriend.invoke(tonda, new Object[] {"Helena"});
//precteni jmena
Method getName = humanClass.getMethod("getName",new Class[] {});
String name = (String)getName.invoke(tonda, new Object[] {});
//precteni kamaradu
Method obtainFriends = humanClass.getMethod("obtainFriends",new Class[] {});
Vector friends = (Vector)obtainFriends.invoke(tonda, new Object[] {});
//vypis kamaradu
System.out.println(name+" ma kamarady:");
Iterator iter = friends.iterator();
while (iter.hasNext())
System.out.println(iter.next()); |
Všimněte si, prosím, především toho, že reflexe nezná pojem „vlastnost objektu“. Chceme-li pracovat s instancemi reflexí prozkoumané třídy, můžeme jedině invokovat nalezené metody. To samozřejmě nevadí, pokud se spokojíme s nahlížením na zpracovávané objekty na takto nízké úrovni. Je zapotřebí vůbec nějaké „vyšší“ úrovně nahlížení na objekty? Není to nezbytné, ale výsledný kód by tak mohl být přehlednější, méně náchylný k chybám, možná kratší, více by odpovídal zásadám objektového programování. Sun si potřebu podobného nástroje uvědomil, proto navrhl a implementoval nadstavbu reflexe pro pohodlnější práci s objekty odpovídající specifikaci JavaBeans a nazval ji introspekce. Jak se introspekce vypořádá se zadáním? Podívejme se:
Příklad A.3. Introspekce
//vytvoreni Tondy
String className = "xermes.areflect.example.HumanBeing";
Class humanClass = HumanBeing.class.forName(className);
Object tonda = humanClass.newInstance();
//nastaveni jmena
BeanInfo humanClassInfo = Introspector.getBeanInfo(humanClass);
PropertyDescriptor[] properties = humanClassInfo.getPropertyDescriptors();
PropertyDescriptor nameProp = null;
for (int i = 0; i < properties.length; i++)
{
if (properties[i].getName().equals("name"))
{
nameProp = properties[i];
break;
}
}
nameProp.getWriteMethod().invoke(tonda, new Object[] {"Tonda"});
//dodani kamaradu
//primo prostredky introspekce nelze
//precteni jmena
String name = (String)nameProp.getReadMethod().invoke(tonda, new Object[] {});
//precteni kamaradu
//primo prostredky introspekce nelze
//vypis kamaradu
System.out.println(name+" ma mozna nejake kamarady."); |
Absenci metody typu getPropertyDescriptor(String name) a z toho plynoucí nutnost procházet všechny vlastnosti můžeme pominout jako nepodstatný detail - pro doplnění by stačil několikařádkový dekorátor. Problém je ale jinde. Introspekce je pevně svázaná se specifikací JavaBeans, a tak není schopná porozumět JavaBeans nekomatibilním vlastnostem - tedy například přátelům z našeho příkladu. Jediný tvar vícenásobných vlastností, kterým introspekce rozumí, je takovýto: beans
public Bah[] getFoo(); public void setFoo(Bah a[]); public Bah getFoo(int a); public void setFoo(int a, Bah b); |
Klasická pole ovšem nanabízejí takovou flexibilitu, jako velice oblíbené kolekce z j2sdk, a tak v mnoha případech nejsou příliš vhodná. Je tedy nějaká možnost pro práci s objekty na stejně abstraktní úrovni, jako u introspekce, ale bez nepraktických omezení? Taková možnost tady nebyla, proto jsem na reflexi vystavěl balík abstraktní reflexe, který má za úkol právě to. Podívejme se, jak bude vypadat náš příklad s jejím využitím:
Příklad A.4. Abstraktní reflexe
//vytvoreni Tondy
String className = "xermes.areflect.example.HumanBeing";
Class humanClass = HumanBeing.class.forName(className);
Object tonda = humanClass.newInstance();
//nastaveni jmena
AClass humanAClass = AFactory.getAClass(humanClass);
TraitSimple nameTrait = (TraitSimple)humanAClass.getTrait("name");
nameTrait.set(tonda, "Tonda");
//dodani kamaradu
TraitMultiple friendsTrait = (TraitMultiple)humanAClass.getTrait("friend");
friendsTrait.add(tonda, "Jirka");
friendsTrait.add(tonda, "Helena");
//precteni jmena
String name = (String)nameTrait.get(tonda);
//precteni kamaradu
Vector friends = (Vector)friendsTrait.obtain(tonda);
//vypis kamaradu
System.out.println(name+" ma kamarady:");
Iterator iter = friends.iterator();
while (iter.hasNext())
System.out.println(iter.next()); |
Abstraktní reflexe pohlíží na objekt jako na soubor rozpoznaných rysů (traits). Co je rys? Rysem může být především vlastnost ve smyslu jak ji chápe specifikace JavaBeans (tedy nějaká množina metod, tzv. „accessors“, zprostředkovávajících přístup k datové položce). Rysem ovšem mohou být stejně tak snadno veřejná datová pole (fields), u vícenásobných rysů třeba standardní pole, kolekce či různé uživatelské množiny metod. Ovšem rysem je jednoduše řečeno cokoliv, co jako rys rozpozná implementace k tomu určeného rozhraní Finder. Uživatel abstraktní reflexe může zvolit z dodaných „hledačů“ nebo implementovat svůj, naprosto specifický. A co je zásadní, programu, který abstraktní reflexi využije je úplně jedno, jak objekty vnitřně i navenek vypadají, pokud hledač najde správné rysy.
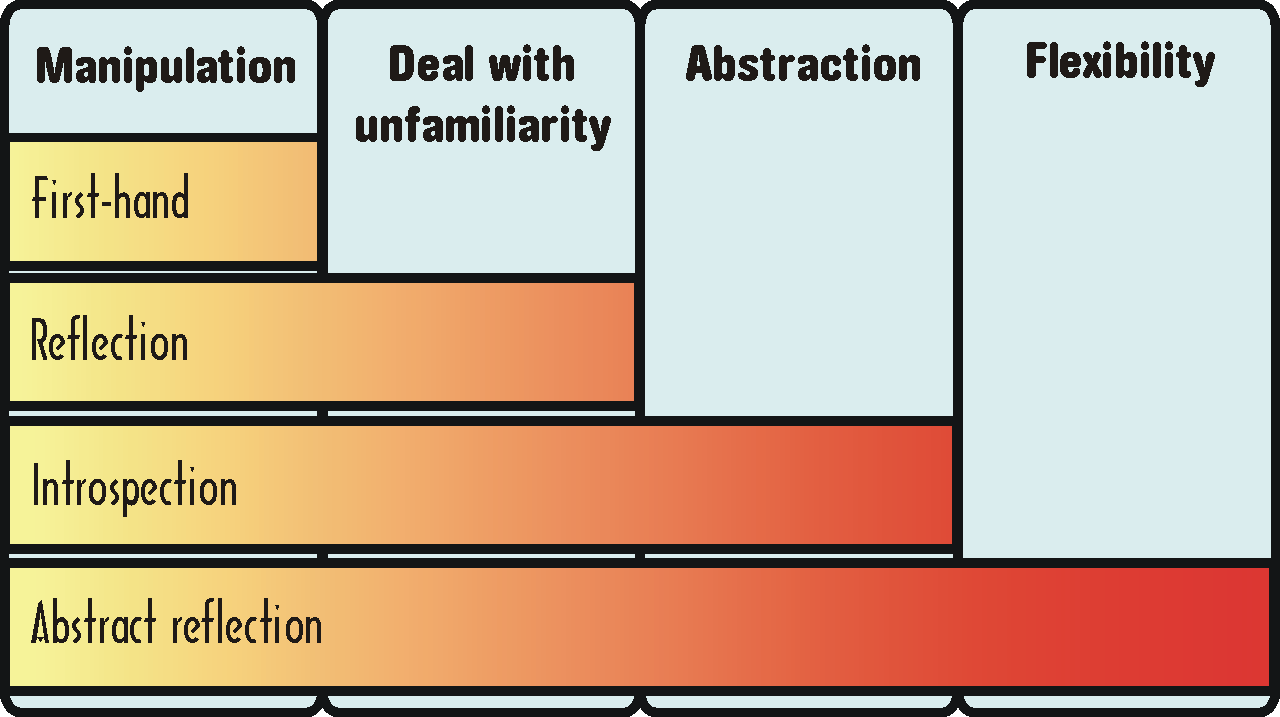
Jak vidíte, abstraktní reflexe je sama o sobě docela rozsáhlým nástrojem a myslím, že by do budoucna jistě našla uplatnění i mimo vlastní projekt Xermes. Balík by se proto mohl oddělit a začít žít svým vlastním životem. Použitelný bude všude tam, kde situace vyžaduje práci s rysy předem neznámých objektů. Generování uživatelského rozhraní z modelu je typicky vhodnou aplikací, ale určitě ne jedinou.
Až část serverová se přímo podílí na hlavním úkolu Xermesu - vytváření uživatelského rozhraní. Jak zapadá do kontextu celé aplikace možná ozřejmí následující shrnutí požadavků, na server kladených. Server má být především odpovědný za:
vytvoření abstraktního popisu tříd, jejichž objekty mají být zpřístupněny uživateli.
předání dat obsažených v objektech uživatelskému rozhraní.
přijmutí dat odpovídajících známým třídám od uživatele a vytvoření, zrušení či změnu příslušných objektů v modelu.
Pro dosažení těchto cílů, musí být schopný splnit ještě následující dílčí úkoly:
„napojení“ se na model
převod dat objektu do podoby vhodné pro přenos a zpracování klientem
převod dat zaslaných klientem do podoby konkrétních objektů
odposlouchávání nějakého portu pro vlastní komunikaci
vlastní komunikace, která bude jak jednoducá, tak schopná prostoupit maximálním počtem i těch hodně restriktivních firewallů
Kromě těchto nezbytných úkolů, musí být rovněž připravený na rozšíření zejména v těchto oblastech:
integrovat libovolným způsobem model - můstek mezi serverem a modelem musí být dostatečně flexibilní
bude-li server i klient pracovat s nějakými primitivními datovými typy, musí být snadné jejich doplňování a změna dle obecných trendů nebo potřeb konkrétní aplikace
bezpečnost (security) - hlídání sezení, logování, ověřování práv uživatele, monitorování, dohlížení
integrace klientů, kteří případně nebudou znát vnitřní komunikační jazyk Xermesu, ale jazyk, který jim bude vlastní bude funkčně dostatečný, aby jej bylo možné namapovat na ten vnitřní
obecně jakékoliv funkční rozšíření
Všechny tyto cíle byly sledovány při návrhu a vývoji serverové části Xermesu. Architektura především nesmí být příliš monolitická, protože takové řešení by neumožnilo požadovanou flexibilitu. Zvolené řešení je nakonec trochu podobné modelu ISO/OSI, tedy vrstevnaté (layered). Na obrázku jsou zachyceny hlavní vrstvy, nezbytné pro funkčnost.

Ze vztahů jednotlivých prvků vidíme, že Xermes je s aplikací propojen důsledně v části modelu (a nikoliv úložiště). Pro zajištění tohoto propojení Xermes definuje perzistor (XePersistor), jehož implementace obstará vše nezbytné. Možná může být tento název matoucí - vždyť je napojen na model a nikoliv na úložiště (tedy vlastního poskytovatele perzistence). Z hlediska Xermesu je ale vše, co je postoupeno modelu, klasifikováno jako perzistentní a je na modelu, jakým způsobem si perzistenci zajistí. Pro testovací účely, ale i jednoduchá nasazení je XePersistor implementován třídou XePersistorSimple, které stačí ke spokojenosti pouze předat kolekci objektů z modelu při jeho vytváření. Ovšem může být použita jakákoliv jiná implementace. Perzistor je jediné zásadní místo, kde je použito abstraktní reflexe.
Při prozkoumávání tříd mohou být abstraktní reflexí nalezeny vlastnosti typu jiného vyššího objektu, nebo tzv. primitivní (atomické). Jako primitivní datové typy Xermes chápe vše, co jako primitivní rozpozná třída Primitives v balíčku primitive. V tomto balíčku jsou rovněž implementace používaného rozhraní Primitive pro čísla, řetězce, boolean a datum (a tyto typy jsou jako pimitivní zahrnuty v Primitives jako výchozí nastavení). Jako s primitivním bude ovšem Xermes pracovat s jakoukoliv , třeba i uživatelskou třídou. Stačí pro to implementovat velice jednoduché rozhraní Primitive a tuto implementaci zařadit do Primitives. Pokud ovšem budete chtít, můžete zde (implementací ClientPrimitive) specifikovat i to, jakým způsobem má klient přistupovat ke generování uživatelského rozhraní pro popisovaný typ, jak má převádět uživatelské vstupy například zadané jako řetězec na instance apod. Proto je balík primitives vyčleněn do samostatného balíku - primitivita zajímá jak abstraktní reflexi, tak server i klienta. Do kapitoly o serveru jsem tento odstavec zařadil, protože server jej potřebuje „nejvíc“.
S perzistorem pracuje výhradně tzv. acilizér (XeAcilizer). Pokud vám tento název připadá podivný, máte pravdu - termím je odvozen od zkratky ACIL, což je na XML založený značkovací jazyk, o kterém se zmíním dále. Acilizér jednoduše mapuje perzistorem nabízené objekty na DOM reprezentaci formátu ACIL. Toto mapování je ovšem jednoduché jen z makroskopického hlediska, vnitřně je docela složité.
DOM strom ACILu je předán objektu implementujícímu rozhraní transformátor (XeTransformer), který je zde pro případný převod do nativního formátu některého z klientů. Vnitřně se skládá ze dvou částí - z dispečéra, a převaděče. Dispečér má za úkol prozkoumat hlavičku požadavku klienta - každá komunikace začne iniciativou klienta. Podle hlavičky dispečér zjistí, jaký formát klient zná a následně vybere vhodný převaděč, který požádá o převod do ACIlu. Do příruční databáze si odloží identifikátor klienta a jím používaný formát pro pozdější využití. Data již ve formátu ACIL předá acilizéru ke zpracování. Jediná implementace převaděče pouze předává ACIL oběma směry dál, tedy jediným v současnosti podporovaným formátem pro komunikaci je právě ACIL, ale nic nebrání vytvoření další implementace. V nejbližší době je plánován převaděč pro HTML s využitím formulářů, dále připadá v úvahu například kombinace HTML a XForms. Až bude vytvořen příslušný převaděč, jako klient poslouží libovolný prohlížeč („browser“).
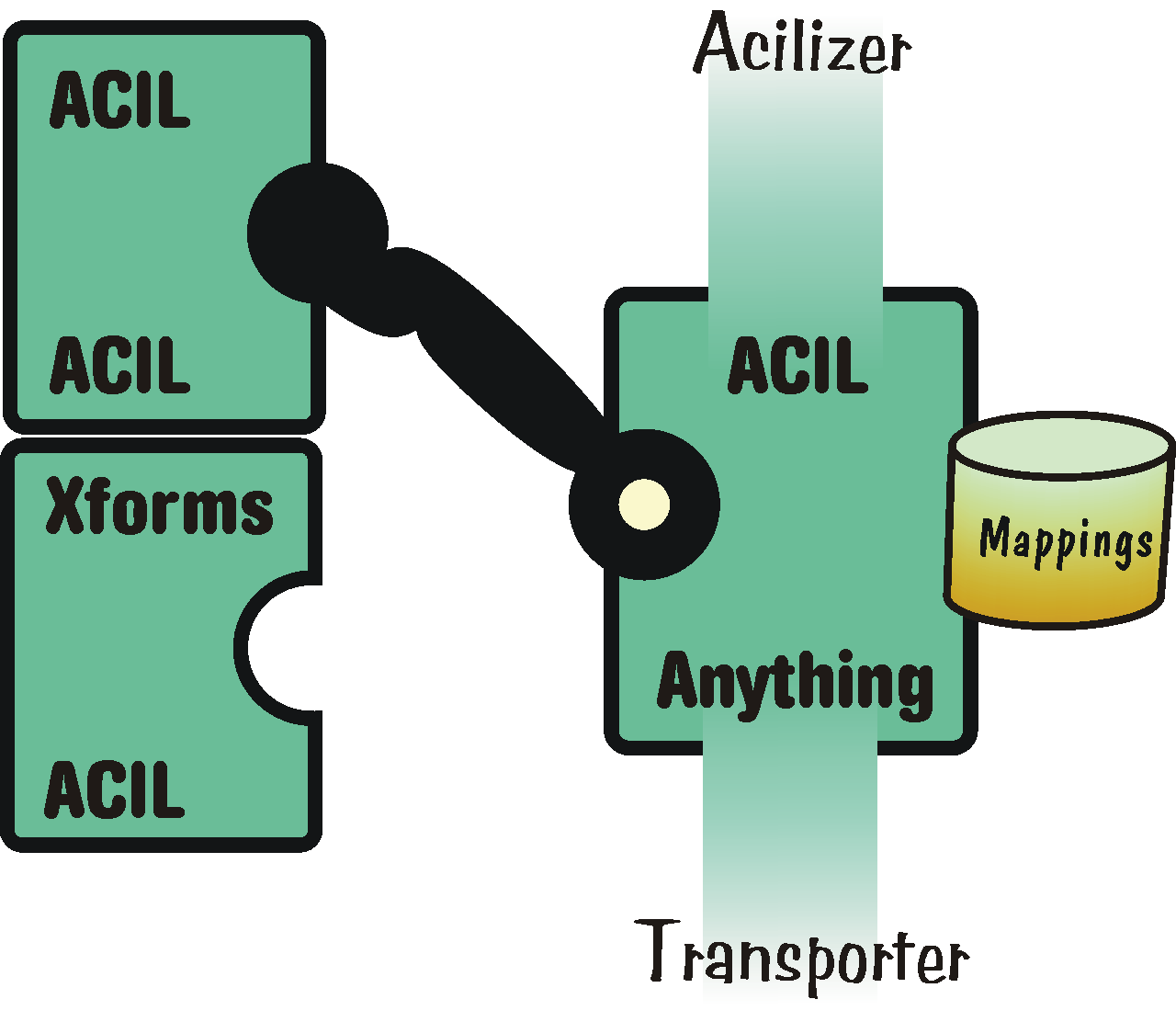
Pokud zachová veřejné rozhraní, transformátor může být vnitřně dále "vrstven" a tak poskytnout takové schopnosti, jako logování uživatelů, šifrování dat apod. Samozřejmě musí být příslušná podpora i na straně klienta.
Výsledná data musí být „narovnána“ - převedena do textové reprezentace XML a odeslána vhodným kanálem ke klientu. Obsluhování tohoto kanálu má na starosti transportér (XeTransporter). Transportér je navržen dostatečně abstraktně, aby jeho implementace mohla pracovat prakticky s čímkoliv, co je schopné data předat. Přestože zatím tak vnitřně členěný není, mohl by v budoucnu následovat architekturu transformátoru a tak pro jeden běžící server zprostředkovat komunikaci více kanály najednou. Zatím existuje pouze implementace, která operuje v rámci běžící aplikace a umožňuje tak varianty infrastruktury desktop (viz 4.1.1 – „Nevrstvená infrastruktura“) a thick client/thin server (viz 4.1.2.1 – „S mohutným klientem“). Doplnit další transportéry by ovšem neměl být zásadní problém.
Které konkrétní třídy budou provádět úkoly jednotlivých vrstev, není nijak napevno „zadrátováno“ do kódu - stačí změnit konfigurační soubor, který vypadá asi takto:
<xsconfig> <modify class="xermes.server.XermesServer"> <simple ref="xeJack" class="xermes.areflect.example.XeJack"/> <simple ref="xeAcilizer" class="xermes.server.XeAcilizerImpl"/> <simple ref="xeTransformer" class="xermes.server.XeTransformerImpl"/> <simple ref="xeTransporter" class="xermes.server.XeTransporterLocalServer"/> </modify> </xsconfig> |
Konfigurační soubor není až zase tak úžasný, pouze dokresluje modularitu a flexibilitu celého systému. Mimochodem je rovněž ve formátu ACIL a pro jeho zpracování je použita abstraktní reflexe.
Pro komunikaci mezi klientem a serverem byly zvažovány některé existující standardy XML. Prvním docela slibným byl XForms (viz ???), který je ale málo abstaktní - umožňuje sestavit stránku formuláře pomocí primitivních komponent, ale nezachovává informace o třídě, které jsou nezbytné pro vytváření měně typických (anebo více přizpůsobených) typů ui. Dalším kandidátem byl formát XMI, sloužící především pro výměnu informací o modelu ve smyslu, jak jej chápe UML (viz B.2 – „Modelovací jazyk“). XMI umožňuje popsat vlastnosti a vzájemné závislosti tříd dostatečně abstraktně, ale jeho možnosti jsou zbytečně rozsáhlé pro účely Xermesu. A zejména, žádný ze zkoumaných standardů nemá dostatečné vyjadřovací schopnosti pro zachycení konkrétních objektů a požadavků uživatele na jejich změny. Proto jsem navrhl formát ACIL (Abstract Class Interchange markup Language), který přebral použitelné koncepty jak z XForms, tak zejména z XMI a přidal to, co žádný standard nenabízel.
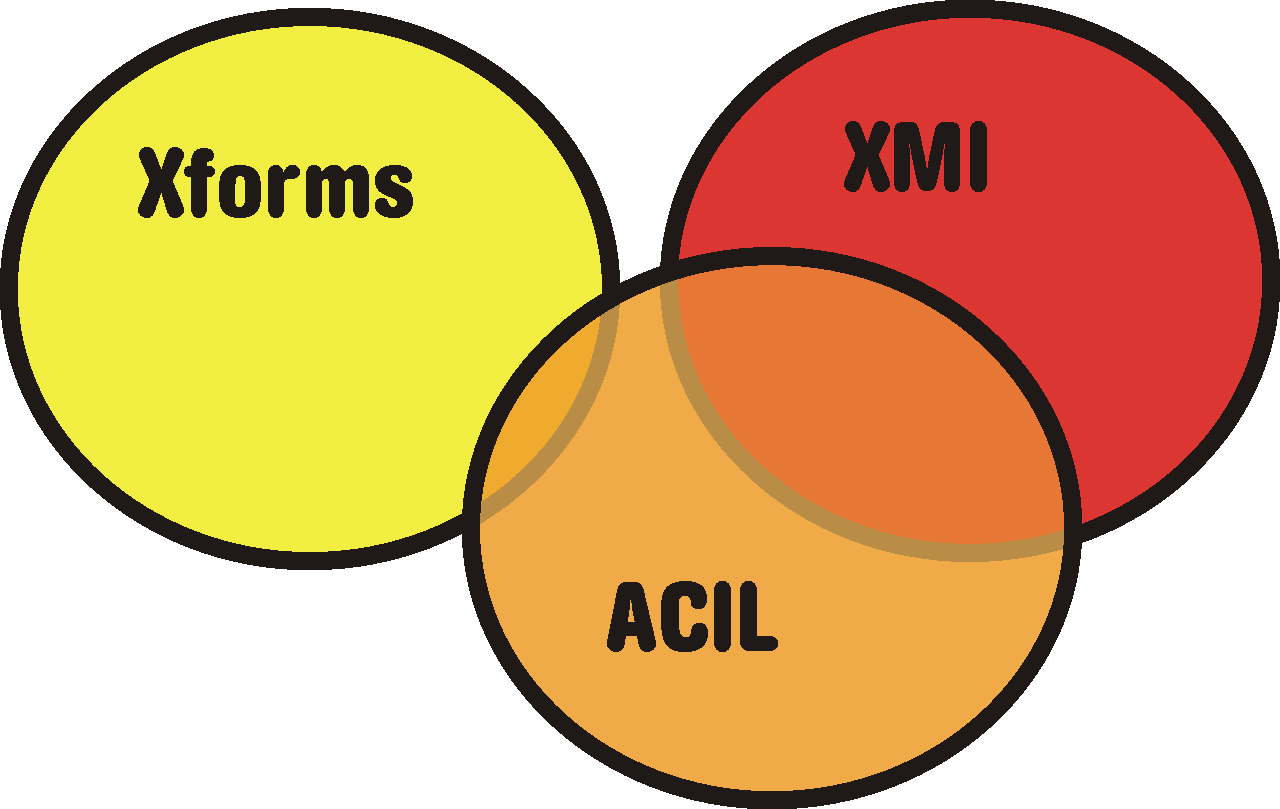
Nepředstavím zde schéma ACILu, protože abych se přiznal, ještě jsem jej nevypracoval. Důvod je prostý - ACIL byl postupně přizpůsobován návrhu Xermesu a některé změny nastaly až v době implementace a ani nyní nemohu tvrdit, že je definitivní. Místo schématu raději představím jednoduchý příklad ACIL dokumentu:
Příklad A.5. Jednoduchý ACIL dokument
<acil meaning="revision"> <interface id="xermes.areflect.example.HumanBeing" autoUi="true"> <multiple id="friend">string</multiple> <simple id="name" identity="true">string</simple> </interface> <create class="xermes.areflect.example.HumanBeing"> <multiple ref="friend"> <create>Jirka</create> <create>Helena</create> </multiple> <simple ref="name">Tonda</simple> </create> </acil> |
Element interface popisuje třídu, kterou má klient za úkol zpřístupnit uživateli, posílá se pouze při prvním výskytu této třídy při vzájemné komunikaci a posílá ho pouze server (tedy nikoliv klient). Atribut autoUi požaduje po klientu okamžité vytvoření příslušných prostředků (nejspíše obrazovky s grafickými prvky). V elementu jsou zejména popsány jednotlivé rysy třídy, ať jednoduché či násobné, jak primitivní, tak komplexní. V příkladu je name rysem primitivním, typu string, jednoduchým. Rys friend je rovněž primitivní, ale násobný a rovněž typu string. Atribut identity označuje ty rysy, které mají být považovány za jednoznačný identifikátor konkrétního objektu. Pokud nejsou tyto klíčové rysy určeny pravidly použitými abstraktní reflexí, Xermes je určí automaticky - použije množinu všech primitivních jednoduchých rysů. Z toho plyne jediný požadavek, který má Xermes na zpracovávané objekty: musí mít alespoň jeden jednoduchý primitivní rys nebo explicitně určený identifikátor, což je ale požadavek velice snadno naplnitelný.
Element create v uživatelském rozhraní vytvoří reprezentaci konkrétního objektu. Podobné jsou element modify a delete. Všechny tři může posílat jak server - tím požaduje příslušné změny v reperezentaci objektů klientem, a stejně tak klient, když zprostředkovává uživatelovy požadavky serveru. V příkladu pro jednoduchost není žadný komplexní rys a ani žádná další pokročilejší konstrukce.
Z části o serveru a ACILu je již zřejmé, že klient nepracuje přímo s objekty, ale s daty v XML formátu. Tomuto rozhodnutí předcházela poměrně rozsáhlá analýza výhod a nevýhod obou těchto řešení. Pokud by klient pracoval přímo s objekty, celý systém by byl především mnohem jednodužší, pravděpodobně několikrát. Při vysoké propustnosti komunikačního kanálu by to bylo i řešení rychlejší. Přineslo by ale některá díčí, ale i fundamentální omezení a nevýhody, v rozporu s požadavky kladenými na Xermes, stanovenými uplatněním ASM principů. Základní výhody XML přístupu ve srovnání s objektovým jsou tyto:
Granularita. Je možné například přenášet objekt do různé hloubky, nebo i částečně, pro různé náhledy apod. Tím se zejména ušetří množství přenášených dat.
Průraznost. Nevýhodou přenosu celých objektů by byla problematičtější komunikace, protože by se musel přenášet objemný obecný binární proud dat a nikoliv stručný a přehledný XML soubor. Přestože to není nemožné, je o něco problematičtější „protlačit“ jiná data než textová (HTML, XML apod.) do míst za firewallem. I za těmi nejrestriktivnějšími z nich je obvykle povolena komunikace HTTP protokolem a také práce s elektronickou poštou (protokoly POP3, SMTP, IMAP apod.). HTTP je optimalizovaný právě pro přenos XML a podobných souborů. V případě absence HTTP by bylo možné použít i poštovních protokolů, byť ne tak snadno a výsledek by byl řádově pomalejší.
Účelnost. Souvisí s bodem předchozím - přenáší se jen to nezbytné pro splnění úkolů a nic navíc.
Čistota. Špatný klient nemůže (technicky to není možné) nevhodně manipulovat s objekty ve snaze plnit úkoly, které patří modelu. K tomu viz zkoumání push a pull přístupu v 7.1.3.1 – „Vytváření dynamického obsahu“.
Flexibilita. Díky oddělení čistých dat z objektu od jeho konkrétní implementace je možné zvýšit úroveň abstrakce - Xermes se tak mnohem snadněji přizpůsobí změnám v modelu.
Nezávislost. Především, klient by nutně musel být napsaný v Javě a to je nepřípustné omezení. Přestože Java je dobrý jazyk pro vytváření modelu aplikace (viz 3.4.3 – „Jazyky interpretované s bytekompilací“), i když ani netvrdím, že pro tento účel vhodný není, ale nemusí být nutně nejlepším jazykem pro vytváření uživatelského rozhraní. Zamysleme se například nad textovým terminálem - i to je případná platforma pro Xermes klienta. V Javě nejsou skuteně rozumné prostředky pro vytváření ui v textovém režimu (nebo jsem na ně nenarazil), zatímco v jiných jazycích ano. A to ani nemluvím o tom, že přeci jenom všude virtuální stroj Javy neběží nebo ani běžet nemůže.
Tento výčet není úplný, ale zejména čistota, nezávislost a flexibilita jsou požadavky tak důležité, že musela být dána přednost XML řešení.
Co je tedy Xermes klient? Klientem může být jakýkoliv program, který dokáže komunikovat ve formátu ACIL nebo v jiném formátu, který bude server podporovat. Ano, kompatibilního klienta můžete vytvořit v libovolném jazyce a navíc může teoreticky dělat cokoliv. Uživatelské rozhraní je chápáno jako brána k lidem-uživatelům. Server ale nijak nepozná, pokud uživatelem nebude člověk, ale třeba nějaký jiný program. Ano, hranice mezi lidmi a programy je z hlediska informačních systémů někdy docela nezřetelná. Ovšem takové využití sice teoreticky možné, ale dosti netypické. Klient napsaný v Javě bude naopak velice běžný a pro snadné implementování klientů v Javě obsahuje standardní distribuce Xermesu v balíčku xermes.client třídy, které shrnují jejich obecnou funkcionalitu. Přidání klienta napsaného v Javě tedy vyžaduje doplnění pouze kódu specifického pro toto konkrétní rozhraní.
Balíček xermes.client.frontswing obsahuje ukázkovou implementaci pro uživatelské rozhraní na bázi Swingu. Najdete v něm formulářové Swingové komponenty pro zpřístupnění jednotlivých tříd vaší aplikace uživateli. Tyto komponenty jsou funkčně zhruba srovnatelné s podobnými komponentami pro RDBMS, jež jsou k dispozici prakticky v každém vývojovém prostředí. V balíčku xermes.client.frontswing.runner je spustitelná aplikace (běžec), která s využitím jmenovaných komponent poskytne uživateli k úpravám objekty všech tříd vaší aplikace. Nevyžaduje prakticky žádnou konfiguraci. Jak vypadá uživatelské rozhraní pro třídu HumanBeing (viz výše)? Takto:
Tato „aplikace“ nabízí uživateli prostředky pro vytváření, rušení, modifikování instancí třídy HumanBeing. Je to skutečně jednoduchá aplikace a celý kód, který musí programátor dodat kromě vlastní třídy HumanBeing, je takovýto:
Příklad A.6. Xermes „Hello world!“ - kód
public class XeJack implements XePersistor
{
private XePersistorSimple persistor;
private Vector cont = new Vector();
public XeJack()
{
loadData();
persistor = new xermes.server.XePersistorSimple(cont);
}
private void loadData()
{
HumanBeing tonda = new HumanBeing();
tonda.setName("Tonda");
tonda.addFriend("Jirka");
tonda.addFriend("Helena");
cont.add(tonda);
}
public Vector get()
{
return persistor.get();
}
public void process(Element phantom) throws XermesJackException
{
persistor.process(phantom);
}
} |
Uživatelem vytvářené objekty budou přibývat ve vektoru cont. Aplikace nemá vyřešenou perzistenci, ale nezapomínejme - to již není úlohou Xermesu (viz 5 – „Úložiště“).
A co složitější aplikace? Vytvořil jsem model jednoduchého programu pro správu kontaktů na lidi, firmy, instituce včetně zachycování vztahů mezi nimi. Výřez z diagramu znázorňujícího tento model vypadá takto:
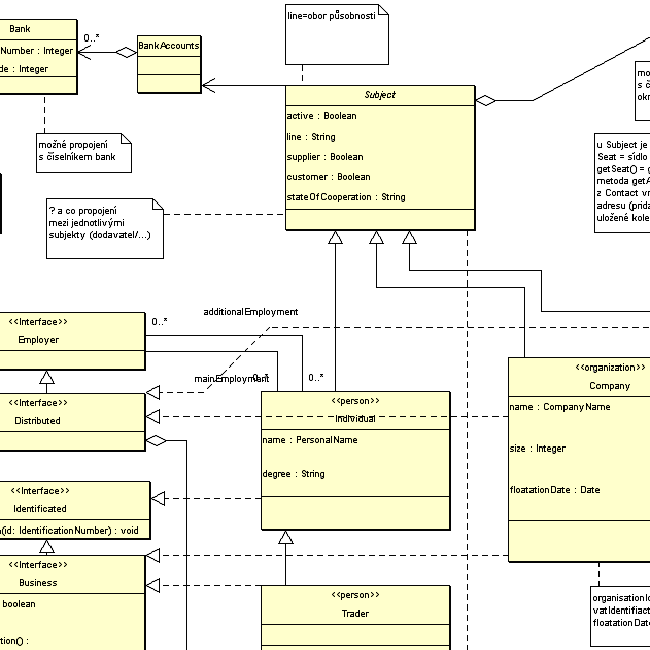
Tento obrázek nemusíte nijak detailně zkoumat - pouze ukazuje, s jak komplexními vztahy si Xermes dokáže poradit - s různými typy asociací a agragací, s dědičností, implementací rozhraní apod. A takto vypadá kousek implementace tohoto modelu, otevřený ve vývojovém prostředí Forte For Java od firmy Sun:
Implementace neobsahuje nic, co by se vztahovalo k uživatelskému rozhraní. Jedinou vazbou mezi ui a modelem je implementace perzistoru, zhruba stejně složitá jako u příkladu výše. Xeremes vygeneruje takové rozhraní (zobrazena je pouze jeho část):
K vytvoření jednoduché aplikace s využitím Xermes běžce (třídy Runneru) je skutečně hračka – stačí k tomu pouze
implementace objektového modelu - toho vás jen tak něco neušetří
třída perzistoru (pár řádků)
a to je vše.
Zmíněné řešení takřka bez práce a uživatelská ne-přívětivost tomu trochu odpovídá. Při programování skutečné aplikace pravděpodobně nevyužijete běžce, ale spíše jednotlivé komponenty, které vsadíte do svého specifického uživatelského rozhraní, které si jinak navrhnete a sestavíte sami a které tedy může vypadat podle vašich představ.
Xermes nabízí ty nezbytné funkce pro implementaci aplikace v souladu s ASM, které dosud chyběly.
Použití Xermesu ve srovnání s konvenčními přístupy k tvorbě ui přinese například tyto výhody:
Snížena redundance informací. Maximum je generováno za běhu na základě informací získaní abstraktní reflexí, přímo z vašeho modelu. Změníte-li model, nemusíte ručně upravovat formuláře tvořící uživatelské rozhraní - komponenty Xermesu se mu okamžitě přizpůsobí.
Méně kódu = méně práce, snadnější správa. Xermes zajistí většinu prezentace, kvalitní perzistenční vrstva (např. OJB) uloží vaše objekty do nějaké databáze. Množství kódu, který se netýká přímo aplikační logiky je omezeno na minimum.
Škálovatelnost. Můžete vytvořit aplikaci, která bude fungovat snadno jako samostatná, v klient/server nebo i třívrstevné architektuře.
Univerzálnost. Nejste pevně omezeni na jeden konkrétní vzhled uživatelského rozhraní a dokonce ani na konkrétní technologii uživatelského rozhraní – zatím je podporovaný Swing, následující v řadě je HTML/forms, přicházejí v úvahu rozhraní pro textové konzole nebo třeba zvuková uživatelská rozhraní…
Konzistentní vzhled a chování. Použitím komponent vyšší úrovně abstrakce než jednoduchých tabulek, textboxů apod. dosáhnete konzistentního vzhledu ui v rámci celé aplikace.
Oddělení vzhledu od funkčnosti = robustnost a snadnější správa. Model je důsledně oddělen od vzhledu, což je široce přijímáno jako jasný klad.
Xermes využívá (a vyžaduje) následující knihovny v uvedených verzích nebo novější:
Sun J2SDK v1.4.0 (freeware)
MetaStuff DOM4J v1.3 (Apache-style)
Jakarta Regexp v1.2 (Apache-style)
Jakarta Log4J v1.2.5 (Apache-style)
Sun JAXP v1.1 (freeware)
Object Mentor JUnit v3.7 (IBM's Common Public License)
Apache Xerces v1.2.3 (Apache-style)
Xermes je zveřejněn pod Apache-style licencí. Ta je natolik svobodná, že vám například dovoluje použít celek nebo i části v komerčních aplikacích bez zásadního omezení - vaše aplikace nemusí být open-source. Autor ovšem nemůže dát žádné záruky, naopak, v současnosti je program ještě ve stádiu vývoje a testování a pokud ho použijete, děláte tak na vlastní riziko. Plné znění licence je takovéto:
============================================================================
The Apache Software License, Version 1.1
============================================================================
Copyright (C) 1999-2000 The Apache Software Foundation. All rights reserved.
Redistribution and use in source and binary forms, with or without modifica-
tion, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice,
this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. The end-user documentation included with the redistribution, if any, must
include the following acknowledgment: "This product includes software
developed by the open source volunteers at xermes.sourceforge.org."
Alternately, this acknowledgment may appear in the software itself, if
and wherever such third-party acknowledgments normally appear.
4. The name "Apache Software Foundation" must not be used to endorse or
promote products derived from this software without prior written
permission. For written permission, please contact apache@apache.org.
The name "Xermes" must not be used to endorse or promote products derived
from this software without prior written permission. For written
permission, please contact dvid@atlas.cz.
5. Products derived from this software may not be called "Apache" nor may
"Apache" appear in their name, without prior written permission of the
Apache Software Foundation.
Products derived from this software may not be called "Xermes" nor may
"Xermes" appear in their name, without prior written permission of the
Xermes founder.
THIS SOFTWARE IS PROVIDED ''AS IS'' AND ANY EXPRESSED OR IMPLIED WARRANTIES,
INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND
FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE
APACHE SOFTWARE FOUNDATION OR ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT,
INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLU-
DING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS
OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. |
Program je open-source, tedy s veřejnými zdrojovými kódy. Díky tomu jej můžete libovolně přizpůsobovat svým potřebám. Pokud něco užitečného doplníte, prosím dejte mi vědět.
Xermes je zhruba použitelný, mnoho chyb bylo odstraněno, ale mnoho jich ještě na odstranění čeká. Proto je nyní prioritou především další intenzivní testování, dále pečlivé zdokumentování kódu a usnadnění využití již nabízených funkcí. Až v dalším kole budou přidávány další funkce, tedy především další typy klientů a transportérů.
Já, tedy David Zejda, jsem projekt navrhl, založil, analyzoval, implementoval, testoval. Případní dobrovolní programátoři, ale i hodnotitelé a testéři jsou nyní více než vítáni! Xermes je silně modulární a může se tak rozrůstat všemi směry.
Ať vám slouží!
Příloha B. Proces vývoje aplikace
- B.1. Proces
- B.2. Modelovací jazyk
- B.3. Řešení problémů nadohled
- B.4. Vztah MDA k ASM
Prakticky nikdo se dnes nebude hádat, že je vhodnější programovat bez předchozí analýzy a návrhu - zejména u středních a větších projektů. Otázkou ale zůstává, jaký vývojový proces zvolit. V této oblasti bylo vypracováno několik uznávaných metodologií, které nejsou příliš kompatibilní a i v některých klíčových otázkách se neshodnou. Nebudu tyto metodologie nijak srovnávat - téma je to docela široké a myslím, že v tomto směru toho bylo napsáno docela dost. Jenom připomenu, že ještě do nedávné doby byl populární tzv. kaskádový vývoj, který spočíval ve snaze nejprve vše detailně analyzovat a vymodelovat a až poté zahájit vlastní programování. Takový postup se prokázal jako nedostatečně flexibilní, neumožňoval také příliš efektivně využívat pracovní sílu a trpěl různými dalšími neduhy. Proto je dnes běžným postupem tzv. iterační vývoj - začne se vytvářet model, ten se postupně převádí do kódu, při tom se zjištují chyby a doposud neidentifikované požadavky, které zpětně ovlivňují model. Některé neduhy mu ovšem zůstaly.
Programátoři přeloží modely do hlaviček programu a vlastní kód dodají ručně. Modely jsou pouhým meziproduktem, jakousi skicou a jsou spravované nezávisle na finálním produktu, kterým je kód - modely netvoří trvalou hodnotu. [modelsbyassets] Teorie svižného modelování (agile modeling) dokonce doporučuje pečlivě u každého modelu již převedeného do kódu zvážit, zda se vyplatí model zachovat a snažit se ho synchronizovat s kódem anebo zda je lepší se ho rovnou zbavit. [agile] Obrázek půjčený z [mde] demostruje takovou ztrátu konzsitence modelu s kódem v průběhu vývojového procesu:
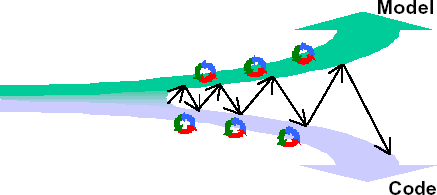
Standardem pro popis objektových modelů aplikací je jazyk UML konzorcia ODMG. Jméno Unified Modeling Language (UML), tedy něco jako „sjednocený jazyk pro modelování“ připomíná fyzikální „univerzální teorii částic“ - jakoby říká "ano, tady je systém schopný zodpovědět všechny otázky vývoje systému". Ale pak přijde trpké prozření - body 1 a 2 jsou z [javauml]:
UML se neustále vyvíjí. Zatímco konvence pro vytváření UML diagramů jsou široce uznávané, metodologie procesů „vespod“ je značně nevyzrálá.
Chybí možnost popsat některé důležité části procesu. Občas je dokonce nějaká používaná funkčnost odstraněna, aniž by byla nahražena odpovídajícím ekvivalentem.
A zejména UML specifikuje abstraktní syntaxi každého diagramu odděleně. To se podobá snaze definovat syntaxi programovacího jazyka a syntaxi metod odděleně, bez vysvětlení, jak spolu souvisejí ani co budou dělat, až bude program spuštěn.[modelsbyassets]
Tyto a další nedostatky se snaží řešit skupina právě vyvíjených standardů konzorcia ODMG - UML2 a CWM (Common Warehouse Metamodel), a dále nová verze XMI pro zachycení a výměnu metamodelů UML diagramů. Všechny tyto standardy jsou definované na základě MOF2 (Meta-Object facility) a zastřešeny MDA (Model Driven Architecture), standardním systémem pro vytváření standardů.
Navrhovaný modelovací jazyk by měl být schopný výstižně popsat všechny klíčové aspekty programu, ale i jeho detaily. Základní koncepty musí odpovídat problémové doméně. Ve srovnání s tím, programovací jazyky včetně těch vyšších jako C++ či Java, jsou mnohem blíž počítači. Ano - hovoříme o možnosti „programování“ aplikací přímo použitím modelovacích jazyků místo jazyků programovacích. Použití modelovacích jazyků ke specifikaci softwaru je tím hlavním, co vedlo k zahájení prací na MDA. S vhodnou technologií bude možné odpovídající programy automatizovaně generovat na základě modelů buď celé anebo alespoň všechny podstatné části. Tato myšlenka, až bude dovedena do konce, způsobí co do zvýšení výkonnosti a spolehlivosti převrat v procesu vývoje programů srovnatelný s vynálezem kompilátoru. [evolution]
Obrázek jsem si půjčil z [mdd].
Ano - platformně specifický kompilátor modelu přeloží UML do výsledného programu. V hantýrce MDA, platformně nezávislý model (PIM) bude namapován kompilátorem modelu na platformě specifický model (PSM). V průběhu této kompilace bude možné ovlivnit strukturu výsledného PSM. [modelsbyassets]
MDE či MDD (Model Driven Engineering, Model Driven Development) je jediný přístup, který může zaručit úplnou konzistenci kódu s modelm v průběhu iteračních cyklů vývoje. Model nese všechnu informaci a kód je pouze projekcí modelu. Navíc v průběhu těchto překladů mohou být prováděny kvalitativní kontroly, které zajistí zachování požadovaných všeobecných i specifických vlastností. [mde]
Navrhovaná specifikace UML musí důsledně oddělit smysl modelu od jeho vizuální reprezentace. Prezentační vrstva musí být schopna reprezentovat stejnou myšlenku různými způsoby, podle potřeb konkrétních vývojářů. Obrázek z [metadata] znázorňuje tuto vrstevnatou architekturu.
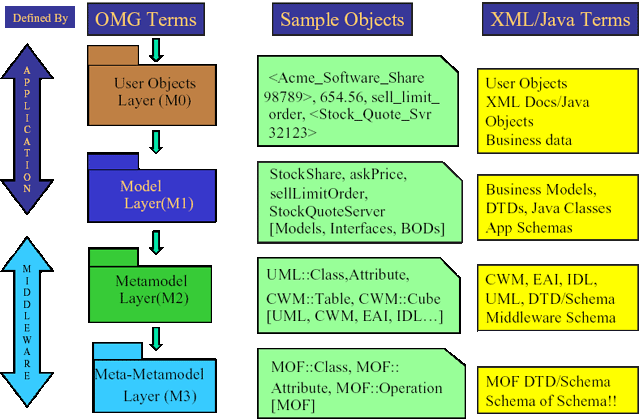
Například jeden vývojář vytvoří stavový diagram, použije přitom pouze přechodů mezi stavy, jiný vytvoří podobný diagram a použije pouze vstupní akce, ale oba budou schopni vyměnit si diagramy a doplňovat je ve svém oblíbeném stylu reprezentace; oba styly jsou totiž matematicky ekvivalentní. Každý z mnoha UML diagramů je pouhou projekcí vlastní specifikace programu. Výskyt elementů v jednom diagramu nutně vede k změnám v jiných diagramech. Například stavový diagram, zachycující odeslání signálu X nějakým objektem implikuje stejný signál na diagramu spolupráce a naopak. [modelsbyassets]
Jaký je tedy vztah MDA a ASM? Pomůže nám v tom, když si uvědomíme, že pojmy architektura a model v ASM znamenají něco jiného než v MDA. Nahraďme proto architekturu termínem „struktura“, pojem „UML jádro“ nechť je synonymem modelu a více nám řekne pan Mellor:
Vykonatelné a přeložitelné UML jádro zachytí abstraktní řešení problému z pohledu vývojáře; nedefinuje strukturu aplikace. Jádro nepotřebuje vědět, jak je signál posílán v době běhu aplikace, důležitý je pro něj pouze abstraktní fakt, že je poslán, že něco se stane dříve a něco jiného později. Rozhodnutí o struktuře softwaru učiněná nezávisle na MDA potom určí dostupné mechanizmy (vzdálené volání, volání funkce, výjimky apod.) a to, který z nich bude řešit tu kterou část modelu. [modelsbyassets]
Doplňme ještě pro úplnost souvislost s vývojovým procesem:
Obrázek znázorňuje něco, co bychom mohli nazvat „modelem řízený vývoj aplikace s modelu podřízenou architekturou“, tedy MDEASM. Tak ošklivou zkratku se ovšem nepokoušejte ani vyslovit, raději na ni rychle zapomeňte...
Na závěr ještě připomenu, že postupy a přínosy MDE jsou silně žádoucí, ale nikoliv nezbytné pro vytvoření aplikace s architekturou ASM. Předmětem zájmu standardu MDA je především proces vývoje modelu, zatímco ASM zkoumá aplikaci jako takovou (její části, vlastnosti ap.) a postup, jakým byla vytvořena je pro ní druhotný. Podle zásad ASM je možné pracovat již dnes, na konečné verze standardů MDA a zejména na odpovídající nástroje si budeme muset ještě nějakou dobu počkat.
Příloha C. CD
Přílohou je CD, které obsahuje zejména tyto části:
- teoretická část (ASM)
Tento dokument ve zdrojovém formátu DocBook.
Tento dokument převedený do některých jiných formátů. Z nich stojí za zmínku například HTML podoba, vhodná pro křížový průzkum - obsahuje hypertextové odkazy.
- praktická část (Xermes)
Kostra programátorské (api) dokumentace Xermesu. Součástí jsou UML diagramy všech tříd Xermesu.
Pro některé klíčové části Xermesu další diagramy - UML diagramy sekvencí, spolupráce apod.
Zdrojové kódy a zkompilovaný tvar Xermesu
Zdrojové kódy a zkompilovaný tvar jednotkových testů (junit tests) v jednotlivých balíčcích. Tyto testy byly vyvíjeny současně s implementací, ale nyní jsou některé z nich zastaralé a vyžadují revizi, jejich výsledky neberte proto příliš normativně.
Zdrojové kódy a zkompilovaný tvar adresáře (viz A.4.1 – „Swing klient“) jako demonstrace některých schopností Xermesu
Všechny cizí knihovny, které jsou třeba pro využívání Xermesu a rovněž vše nezbytné pro snadné spuštění zmíněného adresáře.
Symboly
A
- abstraktní reflexe, Abstraktní reflexe
- accessors, Abstraktní reflexe
- ACIL, ACIL
- acilizér, Server
- agile modeling, Proces
- aplikace, Čtenář
- aplikace na Internetu, Scénář z Internetu
- aplikace s architekturou podřízenou modelu, Požadavky ASM
- ASM, Cíl práce, Požadavky ASM, Vztah MDA k ASM
- ASM aplikace, Požadavky ASM, ASM aplikace jako celek
- assembler, Strukturální programování
- atomické, Server
- AWT, Scénář desktop
B
- bezpečnost, Server
- browser, Server
- business application, Čtenář
- bytekód, Jazyky interpretované s bytekompilací
- běžec, Swing klient
C
D
- data mining, Mnoharozměrné databáze
- dekorátor, Xermes - přehled, Abstraktní reflexe
- desktop, Scénář desktop
- dispečér, Server
- document-management, Řešení v souladu s požadavky
- dolování informací, Logické, deklarativní, pravidlové apod.
- DTD, Schéma
- dvouvrstevná infrastruktura, Dvouvrstevná infrastruktura
- dědičnost, Data a procesy ve vhodné kombinaci
E
- encapsulating, Data a procesy ve vhodné kombinaci
- ERD diagram, Data odděleně od procesů
F
- flexibilita, Klient
- formuláře, Řešení v souladu s požadavky
G
- granularita, Klient
H
- hledač, Abstraktní reflexe
- HTML forms, Formuláře
- HTML formuláře, Formuláře, Řešení v souladu s požadavky
I
- impedance mismatch, Objektově-relační mapování
- impedanční nesoulad, Objektově-relační mapování
- informační systém, Čtenář
- infrastruktura, Infrastruktura
- inheritance, Data a procesy ve vhodné kombinaci
- interpretované, Jazyky interpretované
- interpretované s bytekompilací, Jazyky interpretované s bytekompilací
- interpretovaný, Procedurální
- introspekce, Xermes - přehled, Abstraktní reflexe
- is, Čtenář
- ISO/OSI, Server
- iterační vývoj, Proces
J
- Java, Procedurální, Jazyky interpretované s bytekompilací, Řešení problémů nadohled
- Java applet, Scénář z intranetu
- Java Virtual Machine, Jazyky interpretované s bytekompilací
- JavaBeans, XML mapování, Xermes - přehled, Abstraktní reflexe
- JavaScript, Jazyky interpretované
- JAXB, XML mapování
- JDO, Snahy o univerzální přístup, Jakarta OJB
- JFC, Scénář desktop
- JOX, XML mapování
- JVM, Jazyky interpretované s bytekompilací
K
- kaskádový vývoj, Proces
- KBML, XML mapování
- klient-server, Dvouvrstevná infrastruktura
- knihovny, Strukturální programování, Jazyky kompilované, Jazyky interpretované
- kolekce, Abstraktní reflexe
- kompilované, Jazyky kompilované
- kompilovaný, Procedurální
- konzistence, Přínosy
- konzsitence modelu s kódem, Proces
- kód, Proces
L
- layered, Server
- LDAP, Stromové struktury, Řešení v souladu s požadavky
- legacy, Běžné chyby
- licence, Licence
- LISP, Logické, deklarativní, pravidlové apod., Jazyky interpretované
M
- MDA, Cíl práce, Řešení problémů nadohled, Vztah MDA k ASM
- MDBMS, Mnoharozměrné databáze
- MDD, Řešení problémů nadohled
- MDE, Řešení problémů nadohled
- mnoharozměrné databáze, Mnoharozměrné databáze
- mobilní aplikace, Scénář mobilní
- model, Model, Shrnutí možností, ASM aplikace jako celek, Proces
- MOF2, Řešení problémů nadohled
- mohutný klient, S mohutným klientem
- multilayered, Třívrstevná infrastruktura
- MVC, Scénář z Internetu
N
- neuživatelské rozhraní, Neuživatelské rozhraní
- nevrstvená infrastruktura, Nevrstvená infrastruktura
- nezávislost, Klient
O
- O2R, Objektově-relační mapování
- obchodní aplikace, Čtenář
- Object Pascal, Procedurální
- objekt, Data a procesy ve vhodné kombinaci
- objektový model, Data a procesy ve vhodné kombinaci, Řešení v souladu s požadavky
- objektově orientované databázové systémy, Objektově orientované databázové systémy
- objektově-relační mapování, Objektově-relační mapování , Řešení v souladu s požadavky
- objektově-relační technologie, Objektově-relační technologie
- ODMG, Objektově orientované databázové systémy, Snahy o univerzální přístup, Jakarta OJB, Modelovací jazyk
- OJB, Jakarta OJB
- OLAP, Mnoharozměrné databáze
- On-Line Analytical Processing, Mnoharozměrné databáze
- OODBMS, Objektově orientované databázové systémy, Řešení v souladu s požadavky
- open-source, Řešení v souladu s požadavky, Procedurální, Jakarta OJB, Vytváření dynamického obsahu, Licence
- ORDBMS, Objektově-relační technologie
P
- PDF, Tiskárna
- Perl, Jazyky interpretované
- perzistence, Úložiště
- perzistor, Server
- PHP, Jazyky interpretované
- PIM, Řešení problémů nadohled
- platforma, Platforma, Shrnutí možností
- PortableDocumentFormat, Tiskárna
- PostScript, Tiskárna
- požadavek ASM, Požadavky ASM
- primitivní, Server
- primární cíle ASM, Požadavky ASM
- princip obalu, Požadavky ASM, Závěry a doporučení
- pro hendikepované, Scénář hendikepovaní
- proces, Proces
- programy na dálku, Scénář z intranetu
- prohlížeč, Server
- Prolog, Logické, deklarativní, pravidlové apod., Jazyky interpretované
- práce s lidskou řečí, Logické, deklarativní, pravidlové apod.
- průraznost, Klient
- PS, Tiskárna
- PSM, Řešení problémů nadohled
- pull, Vytváření dynamického obsahu
- push, Vytváření dynamického obsahu
- Python, Jazyky interpretované
- přenositelnost, Řešení v souladu s požadavky
- převaděč, Server
R
- RDBMS, Objektově-relační mapování , Řešení v souladu s požadavky
- redundance informací, Přínosy
- reflexe, Xermes - přehled, Abstraktní reflexe
- registry, Stromové struktury
- relační databáze, Objektově-relační mapování
- relační model, Data odděleně od procesů, Řešení v souladu s požadavky
- RichTextFormat, Tiskárna
- rozpoznávání tvarů, Logické, deklarativní, pravidlové apod.
- RTF, Tiskárna
- rys, Abstraktní reflexe, ACIL
S
- ScalableVectorGraphic, Tiskárna
- Scheme, Logické, deklarativní, pravidlové apod., Jazyky interpretované
- security, Server
- Serializace, Serializace
- servlety, Vytváření dynamického obsahu
- skriptovací jazyky, Jazyky interpretované, Vytváření dynamického obsahu
- Smalltalk, Procedurální, Jazyky interpretované s bytekompilací
- stromový model, Model založený na XML, Řešení v souladu s požadavky
- struktura, Vztah MDA k ASM
- strukturální analýza, Relační model
- strukturální programování, Data odděleně od procesů, Řešení v souladu s požadavky
- SVG, Tiskárna
- Swing, Scénář desktop, Scénář z intranetu, Scénář hendikepovaní, Řešení v souladu s požadavky, Swing klient
- systémy pro správu dokumentů, Řešení v souladu s požadavky
T
- Tcl, Jazyky interpretované
- template engines, Vytváření dynamického obsahu
- tenký klient, S tenkým klientem
- TeX, Tiskárna
- thick client, S mohutným klientem
- thin client, S tenkým klientem
- three-tier, Třívrstevná infrastruktura
- tiskové sestavy, Shrnutí možností
- transformace, Řešení v souladu s požadavky
- transformátor, Server
- transportér, Server
- třída, Abstraktní reflexe
- třívrstevná infrastruktura, Třívrstevná infrastruktura
U
- UML, Modelovací jazyk
- UML2, Řešení problémů nadohled
- univerzálnost, Přínosy
- uživatelské rozhraní, Uživatelské rozhraní
V
- vyšší programovací jazyky, Řešení v souladu s požadavky, Řešení problémů nadohled
W
- webaplikace, Scénář z Internetu
- widget, Shrnutí možností
- WML, Scénář mobilní
X
- Xermes, Řešení v souladu s požadavky
- XForms, Formuláře, Scénář mobilní, ACIL
- XHTML, Transformace, Vytváření dynamického obsahu
- XMI, ACIL, Řešení problémů nadohled
- XML, XML mapování, Řešení v souladu s požadavky, XML, Řešení v souladu s požadavky, Server
- XML databáze, Stromové struktury
- XML mapování, XML mapování
- XML model, Data odděleně od procesů, Model založený na XML, Řešení v souladu s požadavky
- XML Schema, Schéma
- XMLC, Vytváření dynamického obsahu, Řešení v souladu s požadavky
- XSLT, Řešení v souladu s požadavky, Transformace
- XUL, Formuláře
- XWindow, Scénář z intranetu
Z
- zapouzdření, Data a procesy ve vhodné kombinaci
- zpracovávání nejasných a neúplných údajů, Logické, deklarativní, pravidlové apod.
[agile] The Object Primer: Introduction to Techniques for Agile Modeling. Ronin International. 2001. http://www.ronin-intl.com.
[beans] JavaBeans API specification. Sun Microsystems. 1997. http://java.sun.com/beans.
[cocoon] Apache Cocoon - project page. Apache Software Foundation. http://xml.apache.org/COCOON.
[csa4b] Client/Server Architectures for Business Information Systems A Pattern Language. EA Generali, Austria. 1997. http://www.sdm.de/g/arcus.
[itl] Cluster Profiling Project, phase 1. National Institute of Standards and Technology. http://www.itl.nist.gov/div895/cmr/cluster/phase1/data_collection.html. 1/1999.
[j2sdk] JavaTM 2 SDK, Standard Edition Documentation Version 1.4.0. Sun Microsystems. http://java.sun.com.
[javauml] Java and UML. Fawcette Technical Publications. 1999. http://www.devx.com.
[jox] JOX, Linking Java Beans and XML With Ease - project page. http://www.wutka.com/jox.html.
[kbml] KBML - The Koala Bean Markup Language - project page. Dyade. http://koala.ilog.fr/.
[kosek] XML pro každého. 2000. http://www.kosek.cz.
[mapping] Mapping Objects To Relational Databases. Ronin International. http://www.AmbySoft.com/mappingObjects.pdf.
[mappatterns] A Few Patterns for Managing Large Application Portfolios. Generali Office Service Consulting AG, Austria. http://www.objectarchitects.de/ObjectArchitects/.
[mdd] Model driven development. Softeam. 1999. http://www.objecteering.com.
[mde] Guarantee permanent Model/Code consistency: Model driven Engineering (MDE) versus Roundtrip engineering (RTE). Softeam. 2000. http://www.objecteering.com.
[ojb] Apache OJB - project page. Apache Software Foundation. http://jakarta.apache.org/ojb.
[scheme] The Scheme Programming Language, Second Edition. Electronically reproduced by permission of Prentice Hall. 1996. http://www.scheme.com/.
[skripty] Skriptovací programovací jazyky. http://www.reboot.cz/index.phtml?id=153.
[svgspec] Scalable Vector Graphics (SVG) 1.0 Specification W3C Recommendation 04. W3C. 9/2001. http://www.w3.org/TR/2001/REC-SVG-20010904/default.htm.
[taks] Třívrstvová architektura klient-server. http://www.fi.muni.cz/~mara/odbc/3u_a/3t_a.html.iso-8859-1.
[tip] Thinking in Patterns with Java. MindView, Inc. 8/2001. http://www.mindview.net/.
[tp] Technologie programování. http://odkazy.internetshopping.cz/internet/technologie_programovani/otazky.htm.
[transformace] XML, díl třetí - Editace, kontrola a transformace XML dokumentů. Root. 22.02.2001. http://www.root.cz.
[wafer] Wafer project. SourceForge. http://www.waferproject.org/index.html.
[xermes] Xermes - interim project page. 2002. http://xermes.sourceforge.org.
[xforms] XForms specification. W3C. http://www.w3.org/MarkUp/Forms.
[xmlcvsjsp] A friendly game of tug of war: XMLC vs. JSP. The Server Side. http://www.theserverside.com/resources/articles/XMLCvsJSP/article.html.
Poděkování: Moje poděkování si zaslouží vedoucí práce, Doc. RNDr. Jaroslava Mikulecká, CSc. za připomínky, které přispěly především ke zpřehlednění textu, dále Ing. Michal Faust za některé faktické údaje v teoretické části, a v neposlední řadě dlouhý zástup vývojářů, výzkumníků, návrhářů a dalších lidí, kteří se podíleli na vytváření DocBooku, použitých programových knihoven a textů ze kterých jsem čerpal.